Dataset Generation
In order to develop, iterate and improve on RAG pipeline performance, a clear framework for experimentation is needed. While well-defined metrics are fundamental to performance benchmarking, equally important is the availability of an appropriate dataset. In the context of applying RAG in government, the ideal dataset should 1) reflect realistic use cases by public officers 2) encapsulate the complexity of public policy.
A Brief Overview of Synthetic Data Generation
As is often the case in ML problems in the real world, large and accurately labeled datasets are a luxury seldom available. In these cases, synthetic data generation is indispensable. When training LLMs, causal language modeling tasks (predicting the next word using only the previous words) and masked language modeling tasks (predicting a randomly masked word within a sentence) are examples of producing labels from unstructured text data.
RAG is fundamentally a question-answering technology, so evaluating RAG pipelines requires valid question-answer pairs that are not easily collated and not straightforward to synthetically generate. Importantly, question-answer pairs must be (mostly) correct, if not it runs the risk of unfair or inaccurate evaluation of RAG pipelines. Unlike causal and masked language modeling where the answer is obvious (we know exactly what word is missing from a sentence), RAG requires a valid ground truth and a well-defined question that asks about that ground truth.
An increasingly popular approach is to reverse-engineer question-answer pairs from documents by leveraging LLMs. The approach is as follows:
- Chunk and index a selected document base
- Sample N contexts from the index
-
For each sampled context, instruct an LLM to generate a question that can be answered entirely by the context
- E.g. A sampled context might be "Singapore's full-year headline inflation was 4.8% in 2023, down from 6.2% in 2022", a valid question might be "What was Singapore's headline inflation in 2023?" and the correct answer is "4.8%"
- Evaluate the RAG against the same document base used to generate the question-answer pairs
One popular package for this is Ragas, which enhances the data generation process by iteratively increasing the complexity of questions using subsequent LLM calls. This is done in two ways:
- When sampling contexts, a filtering step is introduced by prompting LLMs to determine if the sampled context and generated question are suitable, if not they are amended or replaced
-
When generating questions, a base question is first generated then transformed into a more complex question
- E.g. "Context: What was Singapore's headline inflation in 2023 and 2022? Answer: 4.8% in 2023 and 6.2% in 2022" might be transformed into a reasoning question like "Context: How did headline inflation in Singapore change from 2022 to 2023? Answer: Headline inflation decreased from 6.2% in 2022 to 4.8% in 2023"
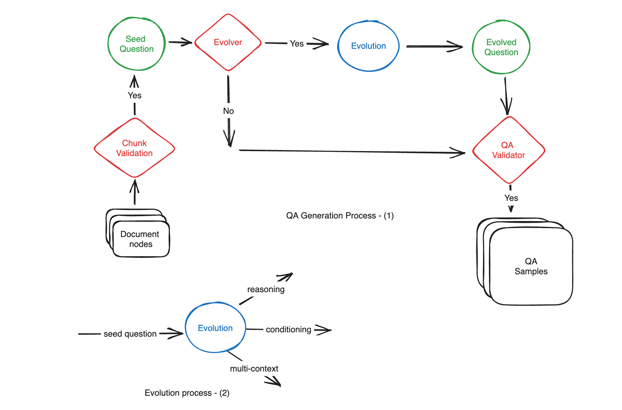
Figure: Diagram of Ragas’ approach to synthetic dataset generation
Limitations
Documents from Hansard were selected as an evaluation dataset because of its broad coverage of public policy and its realistic government use cases. To manage the scale of experiments, only Hansard documents after 2022 were used.
Additionally, documents from Supreme Court Judgements were also used to generate a separate evaluation dataset from a more structured source. Only documents after 2020 were used.
Several issues emerged from using the Ragas package to generate synthetic data:
-
Ragas has a tendency to generate question-answer pairs that either were contrived or not meaningful.
- E.g. The context "Mr Chua Kheng Wee Louis asked the Minister for Foreign Affairs (a) whether he can provide an update on the Ministry's discussions with China on the bilateral visa-free travel arrangement." might generate questions like "What did Mr Chua Kheng Wee Louis ask the Minister for Foreign Affairs?" (not meaningful) or "Can the Minister for Foreign Affairs provide an update on the Ministry's discussions with China on the bilateral visa-free travel arrangement?" (contrived).
- Similarly in the judiciary dataset, using specific text chunks to generate questions lead to questions that were contrived and lacked context.
-
Ragas' generated questions do not provide the full picture with regards to complex policy issues.
- E.g. The context "To help Singaporeans manage the rising cost-of-living, every Singaporean household will receive $500 CDC Vouchers in 2024" might yield the question "What is the government doing to address the rising cost-of-living?" with the answer "They are issuing $500 in CDC Vouchers in 2024.", which is factually correct but just a single instance of cost-of-living related policies.
- Similarly, Supreme Court Judgements can sometimes be extremely long documents with hundreds of thousands of tokens. Questions generated from small chunks of this document do not have access to the broader context of the case.
-
Ragas' approach to filtering contexts and questions relies on LLMs to give a 0-1 score based on some criteria, which is a task that LLMs are poor at. This also significantly inflates latency and tokens consumed by the Ragas algorithm.
- Anecdotally, we observed inconsistent judging where the same context was sometimes deemed suitable and other times in appropriate
Our Approach
Hansard
The approach Ragas (and similar packages) uses for synthetic data generation might work well in simpler contexts (e.g. laws, rules, manuals, structured data, where the full answer is entailed in a single context), but is not well-suited to datasets like Hansard. Based on our observations, there is also limited merit in the filtering approach that Ragas takes due to the inconsistency of LLMs in providing objective, score-based judgements. Instead of relying on available packages, we take a simpler multi-context approach for question generation based on a custom Langchain pipeline.
- Chunk and index Hansard documents
- Determine a set of common topics in Singapore public policy; for example, "Cost-of-living", "COE", "Smart Nation Initiative"
- For each topic, retrieve N (we used 25) documents from the index
- Based on the retrieved documents, instruct an LLM to generate 5-10 questions that can be answered using multiple retrieved contexts
In total, 196 questions were generated. The following additions also helped to improve question quality:
-
Further preprocessing of Hansard documents to remove redundant text
- The first paragraph of each Hansard document typically has a summary, paraphrasing questions addressed to relevant Ministers. These chunks are semantically similar to queries (because they are also questions), but do not actually contain meaningful information. In testing, they were often retrieved but only served to muddle the quality of questions generated, so they are removed.
-
Ensemble retrieval using document titles and document chunks. The titles of Hansard documents are often extremely informative about their content, this helps to retrieve chunks that contain relevant information but may not be retrieved when using basic semantic search.
- Few-shot prompting with clear instructions in the generation prompt, specifically:
- Strict adherence to no paraphrasing of questions already in the contexts
- Only focusing on statements of fact about public policy
- Clear reference to dates and relevant individuals
- Enhancement of documents with metadata like parliamentary seating date and title
An important lesson here is that our synthetic dataset generation approach benefits just as much from RAG pipeline improvements as a regular RAG pipeline. In order to generate the most relevant questions, the most relevant contexts to a given topic must first be retrieved, along with clearly defined rules for questions to follow.
Judiciary
Question generation in Hansard must be multi-context to be realistic. This is less likely to be the case for supreme court judgements, where meaningful questions can still be generated from individual judgements. Hence, we generate a synthetic dataset based on the judiciary dataset with question-answer pairs coming from single documents, not multiple ones.
This single-context approach makes question generation simpler. However, some judiciary documents are extremely long, going well beyond the context window for GPT-4 32K. The immediate option is to chunk each document then generate questions based on individual chunks. As we observed in the Hansard dataset, questions based on specific chunks have the tendency to be contrived or lack context, particularly when prompting the LLM to use only information from the provided chunk. The following approach is used instead:
-
Apply the following filters:
- Documents after 2022 (to keep same size small)
- Documents with less than 30000 tokens (to keep costs and time down)
-
Documents for cases with only one document
- For example, a specific case, Person A v Person B, might have multiple documents. We want to exclude these because they are more likely to reference information beyond the current document, making evaluation more difficult
-
Sample documents randomly from the document subset
-
For each document, generate a summary using LangChain's summarization chain with the 'refine' option.
- Under the 'refine' method, we first chunk the document, then sequentially take in each chunk in chronological order to create a running summary. This ensures that all information in the document is ingested, and the LLM is prompted to include new information from subsequent chunks to ensure exhaustiveness.
-
For each document summary, prompt an LLM to generate 3 questions based entirely on the summary and metadata.
In total, 90 documents were sampled with 3 questions per document, resulting in 270 questions.