Fine-Tuning Methods
Prompt Tuning
Complexity: High
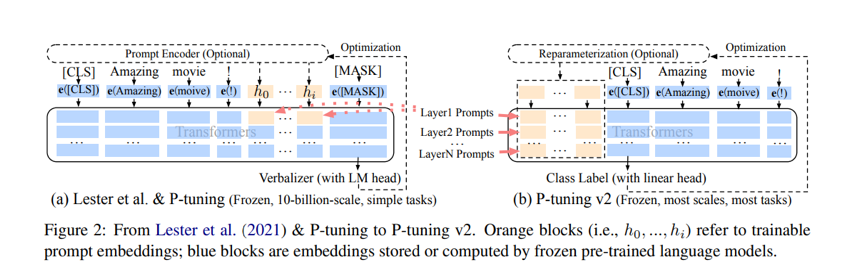
Background: Prompt tuning, prefix tuning and p-tuning are variants of the same approach - tunable, auxiliary embeddings are concatenated to the original prompt embeddings to engineer a better prompt. It is important to note that these are not human readable prompts - they are added to the input query sequence after sequence embedding is performed. Because these auxiliary embeddings are trainable, they can be fine-tuned to improve prompt quality and LLM output for specific downstream tasks. Prompt tuning can be considered a form of Parameter Efficient Fine-Tuning.
Methods:
Prompt Tuning1
Tunable input embeddings are prepended to embeddings of the original prompt.
Prefix Tuning
Tunable embeddings, fed through a regular MLP, are prepended to both the input layer and transformer layers in the network. Conceptually similar to prompt tuning, but performed in several layers rather than just the input layer.
p-tuning23
Tunable embeddings, fed through an LSTM or MLP, are inserted into the input layer. Conceptually similar to prompt tuning, but auxiliary embeddings are not necessarily prepended. The authors find that this improves stability in LLM outputs to small discrete changes in prompts.
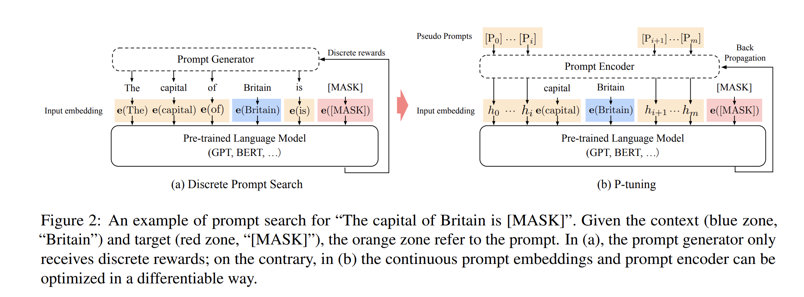
p-tuning V245
The primary difference between p-tuning V2 and the original p-tuning is that p-tuning V2 introduces tunable embeddings to every layer, not just the input layer. Conceptually similar to prefix tuning and p-tuning.
Parameter Efficient Fine-tuning
Complexity: High
Background: Fine-tuning entails updating the weights of a pre-trained LLM using task-specific data to improve its in-domain performance. There are multiple variations to the technique - parameter-efficient fine-tuning only updates a small subset of model weights for computational efficiency, while full fine-tuning requires updating all model weights.
Methods:
LoRA and QLora6
Low-Rank Adaption (LoRA) is a fine-tuning approach stemming from the insight that model weights, which are large matrices, can be decomposed into smaller matrices while still approximately preserving the information they contain7 . QLora is an extension of LoRA that uses quantisation to further improve the efficiency of LoRA.
For instance, a 100x100 matrix decomposed into two separate 100x2 matrices has significantly fewer parameters; 10000 (100x100) vs 400 (100x2x2). The authors of the paper find that, in their tests on GPT-3 175B, using just 0.02% of the total parameters for LoRA produces results superior to full fine-tuning.
More specifically, low-rank decompositions are used to approximate the updates to model weights during fine-tuning, not the weights themselves8. The original model weights are frozen and only the deltas are fine-tuned. These updates can then be added to the model’s original weights. At training, this significantly reduces the computational requirements for fine-tuning a model. At inference, unlike other methods (prefix tuning, adapters, etc) LoRA does not increase latency because there are no additional parameters added to the model.
IA3910
IA311 performs fine-tuning by introducing trainable task-specific vectors to the key, value and feed-forward layers of each transformer block in an encoder-decoder transformer12 . Similar to LoRA, IA3 comes at no additional latency at inference because the total number of parameters in the model are not changed. Additionally, IA3 also allows for mixed-task batches as the activations of each task in the batch can be separately multiplied by its associated learned task vector. Compared to LoRA, IA3 requires even fewer parameters (0.01% vs >0.1% of total parameters in LoRA) while achieving superior performance based on their tests13.
Full Fine-tuning
Complexity: High
Background: In its simplest form, full fine-tuning of a model entails supervised learning over a domain-specific dataset or task. Because all model weights are being optimized, for larger models this entails a tremendous number of gradient calculations and large model checkpoints, making full fine-tuning very costly in both compute and storage. Unless a task or dataset falls significantly outside the domain of a pre-trained LLM, full fine-tuning is unlikely to be necessary.
Methods:
Reinforcement Learning with Human Feedback (RLHF)
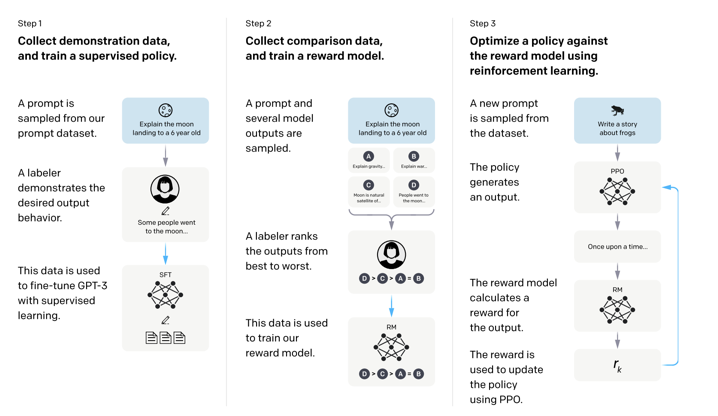
RLHF is a fine-tuning technique with the specific goal of aligning models with some framework of human preference. RLHF is used to fine-tune ChatGPT and GPT-4 to ensure they are helpful, honest and harmless. It proceeds in the following steps:
- A set of actual prompts is sampled from the input prompt distribution and manually labeled by human evaluators. This initial dataset is used in a regular supervised learning procedure to fine-tune the model14, which we call the SFT model.
- A new set of prompts is sampled and several outputs are generated from the SFT model. These responses are ranked by human evaluators, and a reward model15 (RM) is trained to predict the higher ranked output between pairs of outputs16.
- A new set of prompts is sampled and outputs are generated from the SFT model and scored by the RM. The PPO algorithm17 is used to iteratively optimize the SFT model, which in reinforcement learning terms is referred to as the ‘policy’.
-
https://arxiv.org/pdf/2104.08691.pdf ↩
-
https://arxiv.org/pdf/2103.10385.pdf ↩
-
https://github.com/THUDM/P-tuning ↩
-
https://arxiv.org/pdf/2110.07602.pdf ↩
-
https://github.com/THUDM/P-tuning-v2 ↩
-
https://arxiv.org/pdf/2106.09685.pdf ↩
-
https://arxiv.org/pdf/2012.13255.pdf ↩
-
In the paper’s testing, targeting key and query matrices of the transformer layers performed best. ↩
-
https://arxiv.org/pdf/2205.05638.pdf ↩
-
https://huggingface.co/docs/peft/en/conceptual_guides/ia3 ↩
-
As the name suggests, IA3, which stands for Infused Adapter by Inhibiting and Amplifying Inner Activations, is a variation of one of the first PEFT techniques which utilized Adapter modules added to transformer blocks for fine-tuning. ↩
-
In the paper, IA3 is implemented together with modifications to the T0-3B model’s loss functions, which add a length normalization and unlikelihood loss. However, these should be independent of the actual mechanism for IA3. ↩
-
It should be noted that IA3 was tested on T0-3B whereas LoRA was tested on GPT-3 175B (and several other models), and on different datasets. T0-3B is also an encoder-decoder style model whereas popular models like Llama and GPT are decoder only, so it is not clear if results carry over. ↩
-
OpenAI’s RLHF paper notes that, for their first iteration of RLHF, prompts were manually written by labelers rather than sampled. ↩
-
For the RM, OpenAI used an SFT GPT-3 6B with the final unembedding layer removed. ↩
-
Assuming there are 4 generated responses, these are ranked 1>2>3>4. Then, pairs are chosen to train the RM, leading to 4C2 data points. ↩
-
https://huggingface.co/learn/deep-rl-course/unit8/intuition-behind-ppo ↩