Tools for Evaluating Models on GCC
Vertex AI Model Eval and AutoSxS
Vertex AI provides two different tools for evaluating models
- ModelEval evaluates models on certain metrics like AUC, LogLoss and provides results
- AutoSxS compares results from two models and determines which one is the better answer
Note
There are no screenshots for this as currently the only way to invoke this is via code.
AWS Bedrock
Note
Currently only available in selected regions like N. Virginia
AWS Bedrock provides a simple tool to perform model evaluation based on metrics like accuracy and toxicity. It also leverages AWS SageMaker to add in human loops for manual human evaluation, which can be provided by the user or by AWS via AWS Mechanical Turk.
Setting up an evaluation task
Step 1: Select an evaluation task
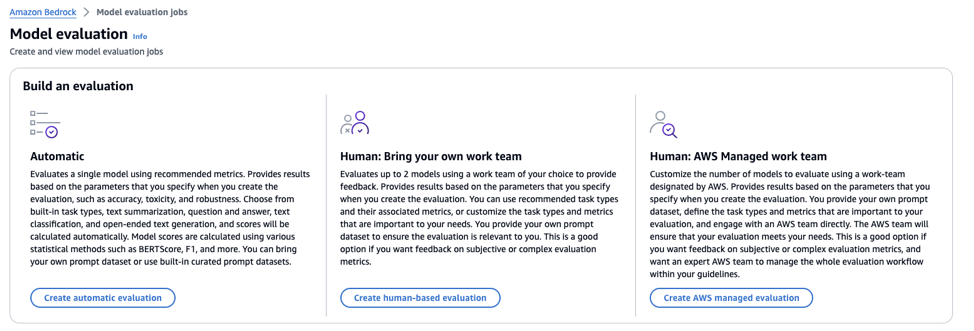
Step 2: Configure the evaluation parameters (automatic evaluation in this example) Note the available evaluation task types.
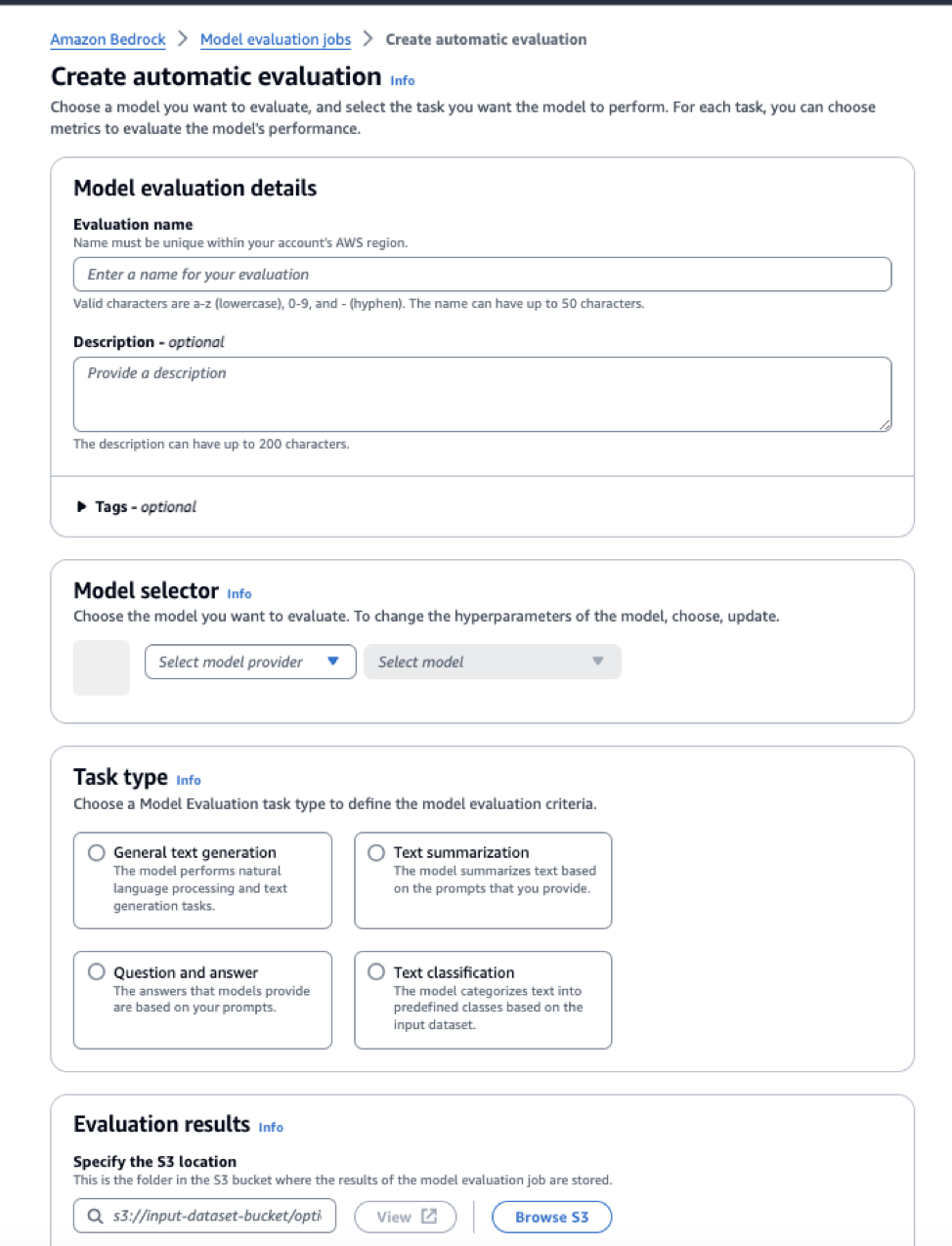
Step 3: Create and wait for evaluation to complete
Step 4: View results The web console provides a summary view of the evaluation results for the metrics like accuracy and toxicity.
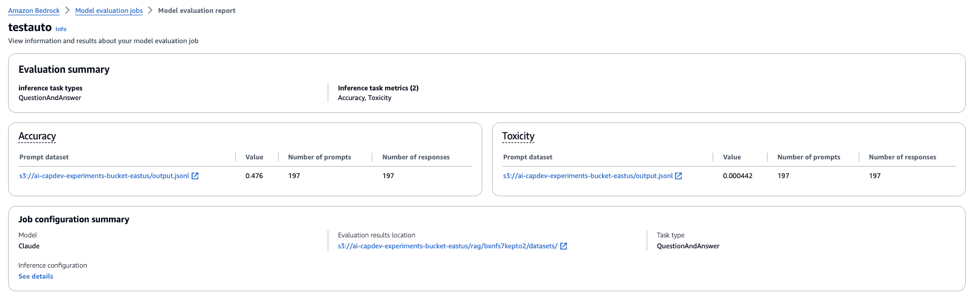
A more detailed per-entry evaluation result can be found in the output file
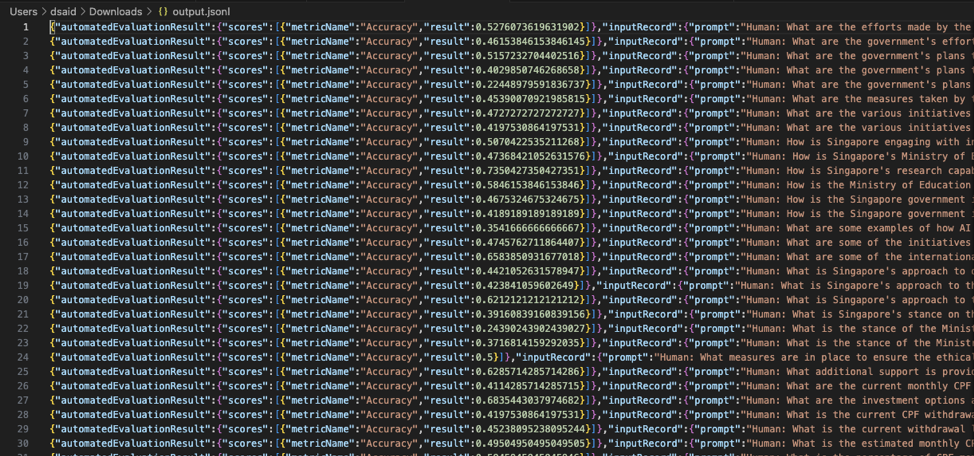
For human based evaluation, your humans will get an annotation task to manually provide evaluation results, instead of it being system generated and tabulated
Dataset Requirements
See here for the latest information.
Azure AI Studio
Note that Azure AI Studio is different from Azure OpenAI Studio
AI Studio provides an evaluation service to measure how well your model performs on primarily Q&A use cases.
Setting up an evaluation task
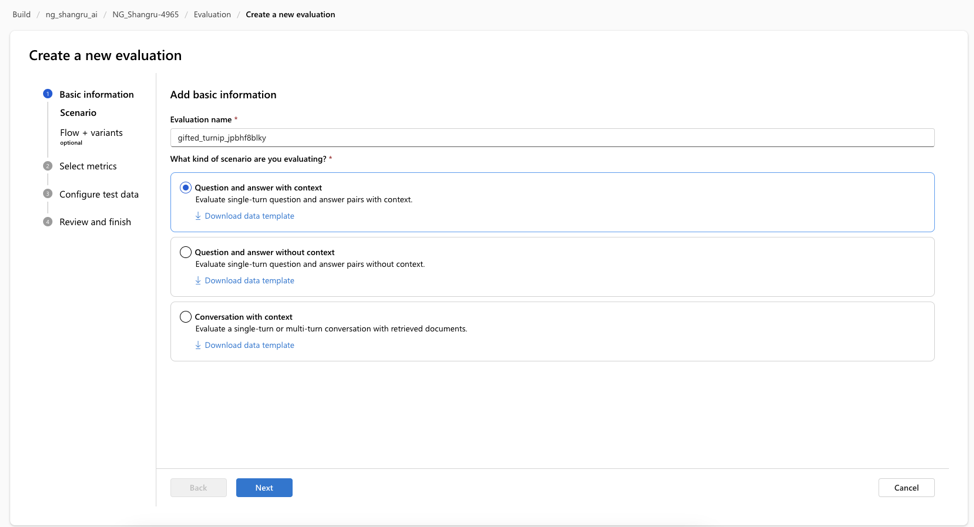
Step 1: Select the type of evaluation task
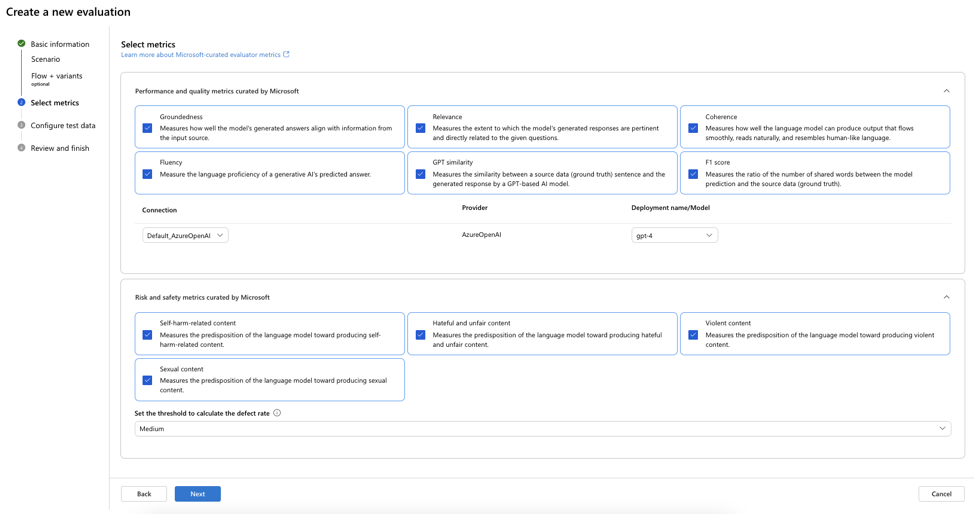
Step 2: Select the metrics to measure
Step 3: Upload dataset and map columns
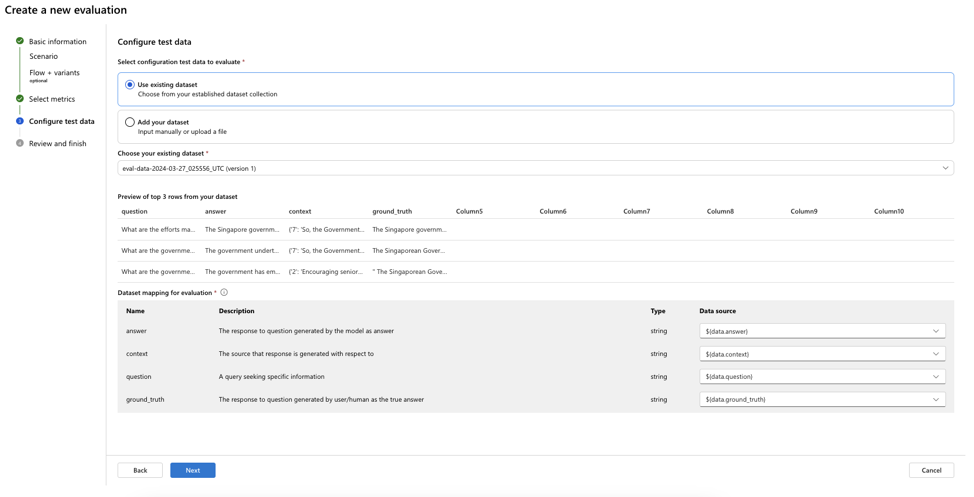
Step 4: Run the evaluation
Step 5: View Results
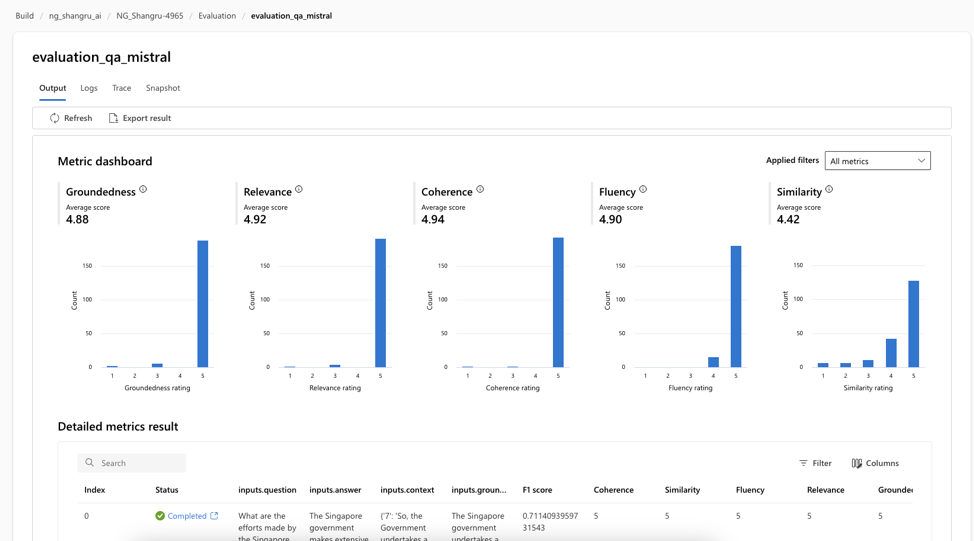
For evaluation on Q&A without context, the tool helps provide an assessment of how well the model answer fits with relevance and groundedness against the source data.
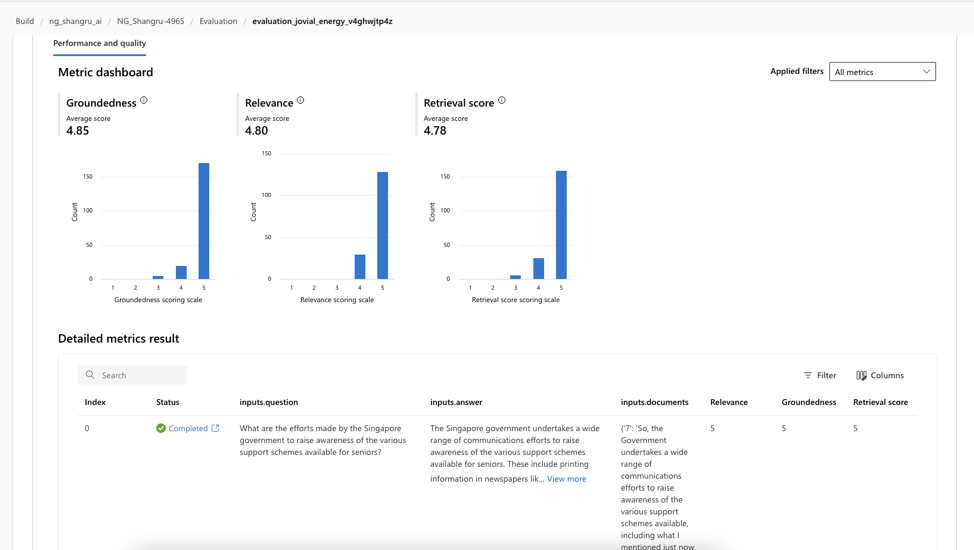
For evaluation on Q&A with context, the tool also provides a summary of the metric scores obtained
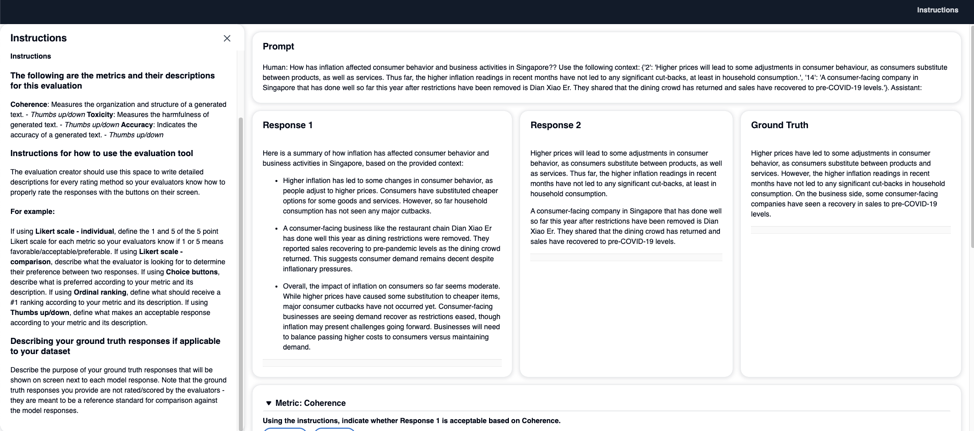
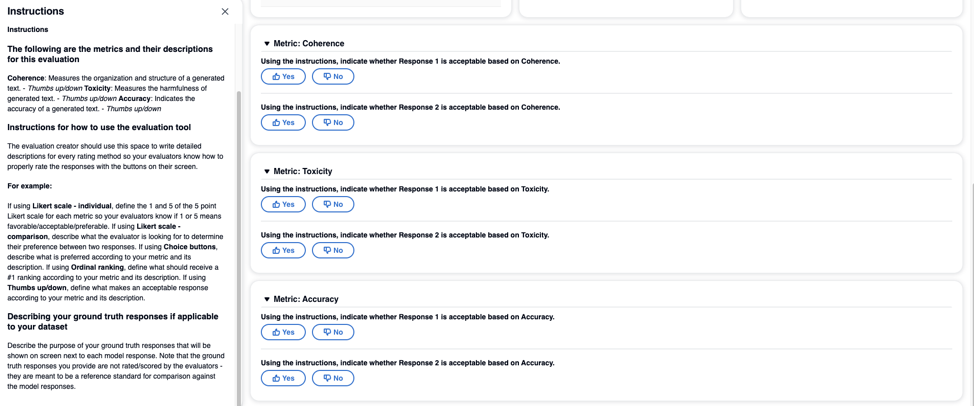
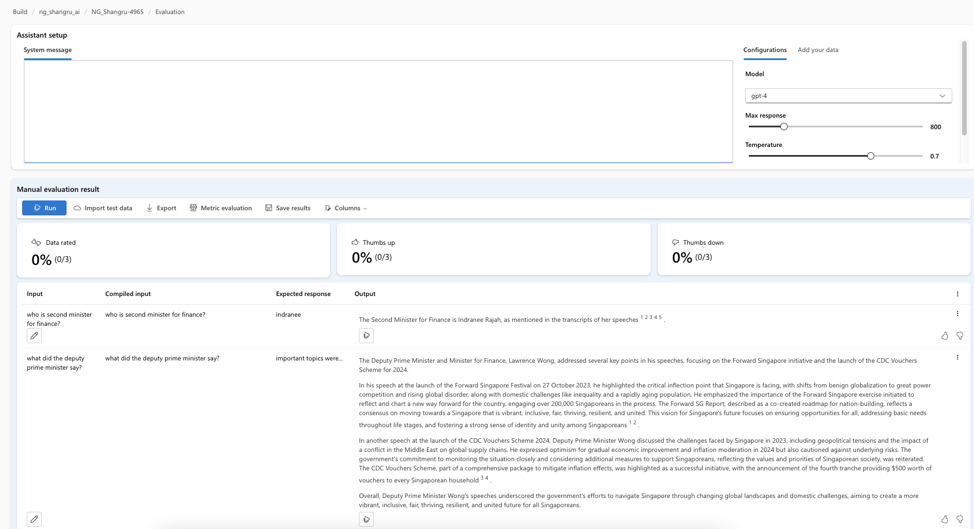
There is also the option of setting up a manual evaluation task where users will manually evaluate each entry and provide a thumbs up or thumbs down
Dataset Requirements
The dataset should contain minimally the question, answer, and ground truth columns. A context column is also required depending on the evaluation task selected.