Evaluating RAG Pipelines
Before deploying a RAG system, we would like to be assured that the system works as desired. We could look at evaluation of RAG systems in 3 different perspectives:
- System view
- Component view
- Safety
System View
In a system view, we are interested in whether the RAG can perform in the desired target tasks satisfactorily. In the context of question and answering, we wanted to know:
a. Whether the system is able to provide any answers that can be found in the knowledge base b. Whether the system is able to handle different kind of users' questions and answer them correctly c. Whether the system is able to identify that it does not have the answer, and not provide hallucinated answers d. Whether the system is able to identify that a question is ambiguous, and would not be able to be answered
In general, we have a ground truth dataset which consists of an exhaustive list of questions and ground truth answers, which we match against the system's generated answers. The performance of the system across the dataset would give us an indication of how well the system's coverage of the factual information in the knowledge base, as well as its ability in handling the different types of questions.
Types of Queries
Simple factual query
These types of queries involve the straightforward retrieval of simple facts from the knowledge base, e.g. how long do we have to keep a backup of a database? The facts in such queries are usually directly found within the knowledge base. This also mirrors similar common use cases of search engines to find out facts
Temporal query
These types of queries require an analysis of the temporal information of retrieved information, e.g. did apple introduce the air tags before or after the launch of the 5th generation ipad pro?
Comparison query
These types of queries require a comparison of evidence from the retrieved information, e.g. did google or netflix report a higher revenue for the year 2023?
Inference query
These queries require that the answer be deduced through reasoning from the retrieved information
Metrics
Traditional approaches
While the traditional metrics are commonly used in summarization and question answering datasets, they are often reported to correlate poorly with human judgements, leading to the development of model based metrics. In short form answers, particularly those involving facts and figures, exact match might be a reasonable metric to use to ensure that the exact figures are given. We list down some of the more common metrics used below.
ROUGE
Recall-Oriented Understudy for Gisting Evaluation1 (ROUGE) is a set of evaluation metrics for evaluating generated translations or summaries against a set of reference translations or summaries. One of the more commonly used sub-metric is the ROUGE-L, which is a F-measure based on the Longest Common Subsequence (LCS) between a candidate and target sentence. The common subsequence of two sentences is the set of words which appear in both sentences in the same order, but do not have to be contiguous. The LCS is then the longest of such common subsequences. For example, the LCS of “the boy went home” and “the boy ran home” is “the boy home”.
Thus given a reference Y of length n and a candidate X of length m, the ROUGE-L score Flcs is computed as follows:
where LCS(X, Y) is the length of the longest common subsequence of X and Y and ß = Plcs/Rlcs.
BLEU
Bilingual Evaluation Understudy2 (BLEU) is an evaluation metric that measures the precision of matching n-grams from the references to the candidate, with a modification that each n-gram in the candidate must be matched to a different n-gram in the references. Thus the number of matches is clipped to the maximum number of times the n-gram appears in the references.
For example, given the reference and candidate as follows:

Where the underlined words show the matching from the reference to the candidate. The modified unigram precision is then computed as [the number of unigram match] / [total number of the unigram] = 2 / 7. To compute the BLEU score for a corpus, the modified precision scores are combined using geometric mean and multiplied by a brevity penalty e(1-r/c) when the total length of the reference corpus r is greater than the total length of the candidate corpus c. This is to prevent very short candidates from receiving very high scores.
METEOR
Metric for Evaluation of Translation with Explicit Ordering3 (METEOR) improves on BLEU by incorporating recall (the number of n-gram matches out of the number of n-grams in the references), and improves on the matching with stemming, synonym mapping and alignment. Precision and recall scores are combined together using harmonic mean with a higher weight (9 is to 1) towards recall vs precision to form the final score. Instead of a simple brevity penalty, it uses a fragmentation penalty to account for gaps and differences in word order.
Exact Match
Exact match4 measures the percentage of exact matches between the candidate and the references. For example, the exact match score of “Happy Birthday” and “Happy New Year” is zero, while the score for “The Colour of Magic (1983)” and “The Colour of Magic (1983)” is one. The exact match score over a set of pairs of candidates and references is the average of the individual exact match score. This metric is useful when the answer is expected to be short and exact, e.g. when the answer is “1983” when asked for the year a movie premiered.
F1 score
F1 score5 measures the average overlap between the candidate and references, where we treat the candidates and references as bags of tokens, where we compute the precision and recall of matching the tokens (words) and hence the corresponding F1 score. For each candidate with multiple references, the maximum F1 score is taken, and the average over all the pairs of candidate and references is computed as the final score.
Model based
The recent developments of model based evaluation metrics tend to correlate better with human judgements. We list down some of the more popular models below.
When based on GPT-4, G-Eval correlates best with human judgements, followed by UniEval and then BertScore in the area of coherence, consistency, fluency and relevancy but requires costly and time consuming calls to GPT-4 for the evaluation.
In spite of the better correlation with human judgements, a common limitation of both traditional and model based system level metrics is the heavy reliance on how the references are worded. For example, an answer that provided the information differently from the references would be penalized even though it answers the question adequately while providing additional help and information. A way to mitigate this would be to provide more references that could cover the possible ways the answers could be provided. However, to do this comprehensively would be difficult, which leads us to the importance of a component view of evaluating the system, which we will elaborate further in the later sections.
BERTScore
BERTScore6 leverages the pre-trained contextual embeddings from BERT which addresses two main issues with traditional metrics: (a) The failure to match paraphrases robustly which leads to performance underestimation, and (b) the failure to capture distant dependencies and penalize semantically critical ordering changes such as when cause and effects are swapped. In BERTScore, the reference and candidate sentences are first tokenised and embedded using BERT. We then match each token x from the reference to each token x from the candidate to compute recall, and the inverse to compute precision. Thus For a reference x and candidate xˆ, the recall, precision, and F1 scores are:
BERTScore applies inverse document frequency (idf) weighting to emphasize more on rare words (which are more indicative for similarity than common words), thus modifying the corresponding recall and precision equations. We show the equation for recall here:
We illustrate the entire BERTScore computation with the following figure:
UniEval
UniEval builds a single model trained in a multi-task setting which evaluates different dimensions of natural language generation, e.g. coherence, relevance, fluency, factual consistency etc. It achieves this by converting evaluation tasks of different dimensions into boolean questions and utilising the model to answer yes or no.
UniEval works by first posing the question to the model (e.g. is this a coherent summary to the document) together with the documents and references, with the model generating a probability of answering affirmative to the question. In this way, the model can be used to evaluate different aspects (e.g. coherence, fluency, etc) by posing different questions. UniEval is first finetuned from a T515 model with multi-task learning involving natural language inference (NLI), opening sentence prediction, judging whether a sentence is linguistically acceptable, and generic question and answer tasks. It is then further finetuned from a dataset crafted to capture different dimensions of evaluations (e.g. coherence, consistency, fluency, relevance, etc). In this stage of finetuning, the model is sequentially finetuned with an increasing set of evaluation dimensions.
The UniEval model is available from the repository: https://github.com/maszhongming/UniEval
G-Eval
G-Eval is a prompt-based evaluator with three main components: 1) a prompt that contains the definition of the evaluation task and the desired evaluation criteria, 2) a chain-of-thoughts (CoT) that is a set of intermediate instructions generated by the LLM describing the detailed evaluation steps, and 3) a scoring function that calls LLM and calculates the score based on the probabilities of the return tokens.
Component View
While the system view aims to measure the performance of the RAG system according to its intended use cases, the component view tries to ensure the robustness of the system by ensuring the individual sub systems works well under various expected scenarios. This provides a second level of assurance that the rag system will continue to work well for cases that are not being tested on the system level. In the following sections, we will dive deeper on the metrics for measuring the performance of the two main components of a RAG system - the retriever and the language model.
Retriever
For the retriever, we want to retrieve all the relevant information needed for the queries as efficiently and as complete as possible. Standard information retrieval metrics are commonly used to measure the performance of a retriever.
For a good retriever, we want it to not only retrieve the relevant information, but also to retrieve them with higher ranks. This would imply that combined with a language model with limited context window, we would have a higher chance of having the relevant information in the context window, and also to have less noise provided to the language model, and hence resulting in a better performing overall system.
Hit@K
Hit@K metric measures the fraction of relevant documents that appears in the top-K retrieved set. For a given query q, let \(R^q\) be the list of documents retrieved pertaining to the query, and \(A^q\) be the list of relevant documents for the query, the Hit@K is defined as:
And the average Hit@K is computed as the average over all queries.
MRR@K
MRR@K (also known as the mean reciprocal rank at K) calculates the average of the reciprocal ranks of the first relevant chunk for each query, considering the top-K retrieved set. This improves upon Hit@K in placing more importance in getting relevant documents in a higher rank.
For a given query q, let Rq be the list of documents retrieved pertaining to the query, and \(A^q\) be the list of relevant documents for the query. The mean reciprocal rank at K for all pairs of \((R^q, A^q)\) from the queries Q is defined as:
where
MAP@K
MAP@K (mean average precision at K) measures the average top-K retrieval precision across all queries. Unlike MRR@K, MAP@K considers beyond the first relevant document, which in the context of an RAG system, is more useful where oftentimes there may be more than one relevant document that is needed to answer the queries.
For a given query q, let \(R^q\) be the list of documents retrieved pertaining to the query, and Aq be the list of relevant documents for the query. The average precision at K (AP@K) for the pair \((R^q, A^q)\) is defined as:
where
The mean average precision at K is then the average of AP@K over all the queries Q:
NDCG@K
NDCG@K (normalised discounted cumulative gain) improves upon MAP@K by considering the documents' different degrees of relevance. For example, a document could contain most of the information required to answer the queries, and could be given a greater weight compared to another document which while is still required for the answer, contains a much smaller proportion of the information needed.
For a given query q, let \(R^q\) be the list of documents retrieved pertaining to the query, and \(G^q\) be the relevance score of each of the documents retrieved. We first define the discounted cumulative gain at K (DCG@K) as:
Let \(S^q\) be the relevance scores of the retrieved documents sorted in descending order. We then define the ideal discounted cumulative gain at K (IDCG@K) as:
And hence the normalized discounted cumulative gain at K (NDCG@K) as:
The NDCG@K for all queries is then computed as the average of the NDCG@K for each query.
Context Recall by Ragas
In the previous metrics, a ground truth of the relevant contexts are required. In situations where ground truth contexts are not available, but that the ground truth answers are, we can use Context recall to measure the effectiveness of the retriever.
We first use large language models such as GPT-4 to infer whether each statement from the ground truth answer can be attributed to the context, by querying the large language model (LLM) with few shot prompting16:
Given a context, and an answer, analyze each sentence in the answer and classify if the sentence can be attributed to the given context or not. Use only "Yes" (1) or "No" (0) as a binary classification. Output json with reason.
question: who won 2020 icc world cup?
context: The 2022 ICC Men's T20 World Cup, held from October 16 to November 13, 2022, in Australia, was the eighth edition of the tournament. Originally scheduled for 2020, it was postponed due to the COVID-19 pandemic. England emerged victorious, defeating Pakistan by five wickets in the final to clinch their second ICC Men's T20 World Cup title.
answer: England
statement: England won the 2022 ICC Men's T20 World Cup.
reason: From context it is clear that England defeated Pakistan to win the World Cup.
attributed: 1
... [more examples]
Thus for each query, context and ground truth answer triplets, we ask the large language model to determine whether each statement can be attributed to the context, and compute the context recall score for the triplet as:
The context recall over all queries is the average of the individual context recalls.
Context Relevancy by Ragas
In the situations where only the queries are available, we could try to estimate the relevancy of the context by asking a large language model on how each sentence of the contexts retrieved are relevant to answering the queries, using the following prompt17:
Please extract relevant sentences from the provided context that is absolutely required answer the following question. If no relevant sentences are found, or if you believe the question cannot be answered from the given context, return the phrase "Insufficient Information". While extracting candidate sentences you're not allowed to make any changes to sentences from given context.
The context relevancy score is then defined as:
The context relevancy over all queries is the average context relevancy score of each query. Similar to context recall, the performance is confounded with the performance of the language model. In addition, this metric does not directly measure the accuracy of the contexts, e.g. a context might be relevant in answering the question but may contain the wrong information.
Context Precision by Ragas
This is similar to the MAP@K metric but does not require ground truth contexts to be provided. Instead, it relies on a large language model to determine whether the context is relevant given the question and ground truth answer. For each query, and context, the LLM queried with few shot prompting18:
Given question, answer and context verify if the context was useful in arriving at the given answer. Give verdict as "1" if useful and "0" if not with json output.
question: who won 2020 icc world cup?
context: The 2022 ICC Men's T20 World Cup, held from October 16 to November 13, 2022, in Australia, was the eighth edition
answer: England
reason: the context was useful in clarifying the situation regarding the 2020 ICC World Cup and indicating that England was the winner of the tournament that was intended to be held in 2020 but actually took place in 2022.
verdict: 1
... [more examples]
The context precision for each context and query pair is thus defined as:
This is useful when we do not have the ground truth contexts, but is preferable over the other metrics such as context recall and context relevancy by ragas as it better captures the importance of ranking of relevant contexts. However, when ground truth contexts are available, MAPK@K or NDCG@K should be preferred due to having fewer sources of errors.
Language Model
We want the language model (usually large language models, usually abbreviated as LLMs) to be able to interpret the questions well, be robust against noise, and grounded to the contexts. Unlike the evaluation of the retriever or the overall system, we are interested in more different aspects of the language model which we think would help in making the overall system robust. We would elaborate more on the various dimensions below.
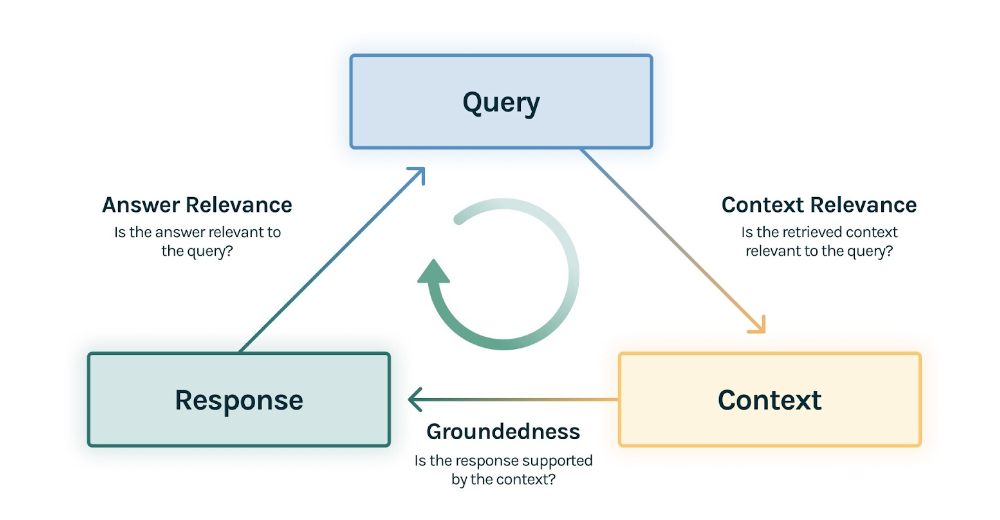
Faithfulness
We would like the language model to remain faithful to the contexts retrieved, and in spite of information bias within the language model that may contradict the knowledge base. As language models (especially large ones) are trained on a vast set of data which we are less likely to have complete knowledge over, we often might not know completely what are the biases in the language model. By grounding on the knowledge base, we are more assured of the information that will be provided to users of the RAG system, and could fix factual inaccuracies more easily by updating the knowledge base.
To measure faithfulness, the common approach is to determine how much of the generated answer can be attributed to the provided contexts to the language model. The state of the art in this area is the AutoAIS model which determines whether each context entails the answer. The AutoAIS7 model has been shown to follow human judgements very well in the literature.
AutoAIS
In AutoAIS, the system tries to estimate the percentage of the sentences in the answer that can be fully attributed to the contexts by human experts based on the Attributable to Identified Sources8 (AIS) human evaluation framework.
Based on the natural language inference (NLI) model from Honovich et al (2022), for each decontextualized sentence s of the answer y, and for each snippet e in the contexts A, let NLI(e, s) be the model probability of e entailing s, then the AutoAIS score is defined as
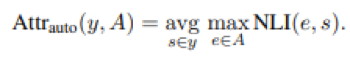
A key component of AutoAIS is the decontextualization of the sentences in the answer. The sentences in the answer are passed into the T5 model by Choi et al (2021)9 together with the contexts to obtain standalone sentences. This ensures that each sentence can be properly attributable to the contexts on its own.
AutoAIS scores correlate strongly with human judgements as can be seen in the figure below:
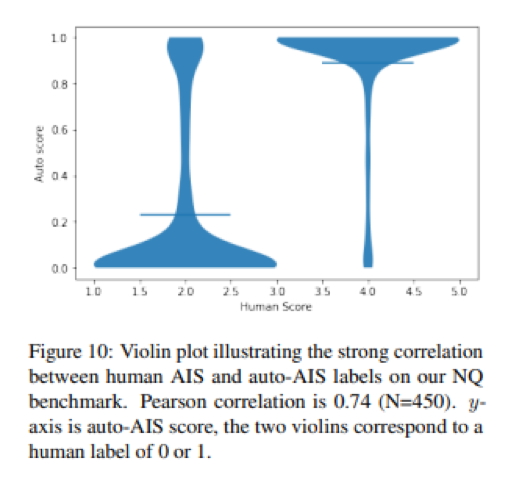
At this point, we would like to point out that AutoAIS measures the ability of the language model to generate an answer based on the contexts retrieved by determining how much of the answer can be attributed to the contexts. This doesn’t measure the correctness of the answer, as the contexts can be wrong. However, a language model that is faithful would assure us that the RAG system would generate grounded responses, and is more likely to be correct if the contexts provided to the language model are relevant.
An example implementation can be found in the repository:
https://github.com/google-research-datasets/attributed-qa
Answer Relevance
We would want the language model to generate answers that address the question posed to the system. This is also a measure of how well the language model is able to understand what the question is asking.
Answer Relevancy by Ragas
One way of measuring the relevance of an answer is to ask a large language model (LLM) to generate a question corresponding to the answer, and then comparing the generated question to the original query.
We query the large language model using few shot prompting14:
Generate a question for the given answer and Identify if answer is noncommittal. Give noncommittal as 1 if the answer is noncommittal and 0 if the answer is committal. A noncommittal answer is one that is evasive, vague, or ambiguous. For example, "I don't know" or "I'm not sure" are noncommittal answers
answer: Albert Einstein was born in Germany
context: Albert Einstein was a German-born theoretical physicist who is widely held to be one of the greatest and most influential scientists of all time
question: Where was Albert Einstein born?
noncommittal: 0
… [more examples]
We then compare the similarity of the embeddings of the generated question and the original query, and define the answer relevancy as:
where E(X) returns the embedding of the question X, q is the original query, qG is the generated question from querying the large language model. For the answer relevancy over all the queries Q, and corresponding generated questions QG, the overall answer relevancy score is:
where committal(qG) is an indicator function which returns one only if the large language model returns that the corresponding answer is committal, i.e. is not evasive, vague or ambiguous. Hence, if any of the answers is non commital, the overall answer relevancy is zero.
Noise Robustness
We would like the language model to be able to generate relevant answers despite having irrelevant information (i.e. noises) in the contexts. This makes the system robust against a retriever that is performing less than ideally.
Given ground truth contexts and answers, we inject additional irrelevant contextual information to the large language model to generate the answers, and compare them with the ground truth answers using the previously described metrics: ROUGE, BLEU, METEOR, Exact Match, F Score, BERTScore, UniEval, G-Eval, AutoAIS, and answer relevancy by Ragas. A better large language model would be able to tolerate noise injection in the context with minimal performance degradation, and is able to handle greater amounts of noise.
Negative Rejection
We would like the language model to refuse to answer when the retrieved contexts do not contain the necessary information for answering the question. This gives us the confidence that the RAG system would avoid giving hallucinated responses for questions which the system failed to retrieve the relevant information, or that the knowledge base does not contain the information. This would also make it easier to determine if there are gaps in the knowledge base which needs to be plugged.
This involves preparing a set of queries whose answers could not be found in the knowledge base, together with a set of ground truth contexts, queries and answers with the relevant contexts randomly replaced with irrelevant ones. In this case, we expect the large language model to respond that they do not have the answer to the question. A corresponding ground truth answer could be constructed and compared to the generated answer using previously described metrics: ROUGE, BLEU, METEOR, Exact Match, F Score, BERTScore, UniEval, and G-Eval.
If the system prompt for the large language model includes a default response when the query could not be answered from the contexts, this default response should be used in the evaluation. In practice, it is recommended that the RAG system includes such a default response, which makes it easier to monitor and determine gaps in the knowledge base.
Safety
Besides the performance of the RAG system to provide the answer that the user is interested in, another key aspect of the system is its robustness to adversarial attacks, as well as whether the system is able to provide responses that are considered safe under some guidelines.
Adversarial Attacks
As the RAG system consists of a language model which is capable beyond answering questions, we want to make sure that queries passed in by the users do not result in the language model performing unintended actions. Unintended actions could be the users making use of the underlying language model to perform their own computations that are not the intended types of queries to the system, or it could be more harmful actions such as to try to extract secret information not in the knowledge base, particularly if the language model has been finetuned on additional confidential data.
Prompt Injection
An user may craft the question in such a way that it overrides the instruction to the language model to perform actions other than trying to answer a question from the knowledge base.
Prompt Leaking
Similarly, a user may also craft the question in such a way, with the intention to leak the internal prompts that we are using.
Jailbreaking
While the system often have guardrails within the language model to prevent them from answering harmful questions, LLM attacks10 are able to automatically generate special queries that can induce unintended purposes, provided the adversary knows the underlying language model.
Guarding against Adversarial attacks
It is recommended to make use of tools such as garak11 or giskard12 to check for vulnerabilities in the model. Garak probes for hallucination, data leakage, prompt injection, misinformation, toxicity generation, jailbreaks, and many other weaknesses. Giskard is an AI quality management system that helps in scanning, testing, debugging, and monitoring all AI models. Part of the suite is the Giskard open-source Python library which scans for vulnerabilities and generates test suites automatically to aid in the Quality Assurance process of ML models and LLMs. It is also recommended to also go through the OWASP list of top 10 critical vulnerabilities13 in large language models.
Tools for Model Evaluation (Available on GCC)
Given the wide range of evaluation metrics available, the first challenge a developer faces in evaluating an RAG pipeline is in selecting the most appropriate metric to use. Once those have been decided, the next challenge is in implementing the metrics. Most of these metrics are provided in open source frameworks like Hugging Face, Langchain, LlamaIndex, Ragas, and UniEval and usually do not need to be coded from scratch. However, using the metrics might require some time to set up, especially if the metrics make use of LLMs to determine the relevancy or correctness of a search result or an answer. Fortunately, few-click, no-code solutions are available in GCC to reduce the effort in model evaluation. We look at three of these solutions and summarise their features based on the following:
- User Interface
- Type of metrics used for auto evaluation
- Support for manual evaluation
- Models used for evaluation
- Support for comparison of multiple models/pipelines
- Models available for use in evaluation
The summary is provided below, and details on how to use each of the tools is given in Tools for Evaluating Models on GCC in the Appendix.
Summary of Model Evaluation Tools in CSPs
| Azure AI Studio | AWS Bedrock | GCP Vertex AI | |
|---|---|---|---|
| UI | Yes | Yes | ??? |
| Metrics Used for Auto Evaluation | Coherence, Fluency, GPT Similarity, F1 Score, Content (self harm, sexual, hateful, violent) | Toxicity, Accuracy, Robustness | AUC, ROC, LogLoss |
| Supports Manual Evaluation | Yes, Thumbs Up / Down, Likert Scale | Yes, Thumbs Up / Down, Likert Scale | No |
| Evaluator Model | - | - | Google's AutoSxS Arbiter |
| Model Comparison | No | Yes (only for manual evaluation) | Yes (AutoSxS) |
| Available models | OpenAI | Titan, Anthropic, AI21, Meta, Mistral, Cohere | Gemini, Meta, Mistral |
| Other points | Easy integration with GPT4 via Azure OpenAI | Not in SG, Probably good for manual evaluation due to integration with work teams via AWS SageMaker | Lack of UI makes it hard to use |
There is currently no standardised way of evaluation across the CSPs, so tooling choice should depend on the use case at hand. For example, if you want to test your model against GPT4, there's only Azure available. Likewise, only AWS currently integrates with AWS SageMaker to have a human loop evaluation mechanism.
Each of these evaluations also provide different metrics when used for auto evaluation, so this should also be considered when selecting a tool.
-
Chin-Yew, Lin. "Rouge: A package for automatic evaluation of summaries." Proceedings of the Workshop on Text Summarization Branches Out, 2004. 2004. ↩
-
Papineni, Kishore, et al. "Bleu: a method for automatic evaluation of machine translation." Proceedings of the 40th annual meeting of the Association for Computational Linguistics. 2002. ↩
-
Banerjee, Satanjeev, and Alon Lavie. "METEOR: An automatic metric for MT evaluation with improved correlation with human judgments." Proceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization. 2005. ↩
-
Rajpurkar, Pranav, et al. "Squad: 100,000+ questions for machine comprehension of text." arXiv preprint arXiv:1606.05250 (2016). ↩
-
Rajpurkar, Pranav, et al. "Squad: 100,000+ questions for machine comprehension of text." arXiv preprint arXiv:1606.05250 (2016). ↩
-
Zhang, Tianyi, et al. "Bertscore: Evaluating text generation with bert." arXiv preprint arXiv:1904.09675 (2019). ↩
-
Gao, Luyu, et al. "Rarr: Researching and revising what language models say, using language models." arXiv preprint arXiv:2210.08726 (2022). ↩
-
Rashkin, Hannah, et al. "Measuring attribution in natural language generation models." Computational Linguistics 49.4 (2023): 777-840. ↩
-
Choi, Eunsol, et al. "Decontextualization: Making sentences stand-alone." Transactions of the Association for Computational Linguistics 9 (2021): 447-461. ↩
-
Zou, Andy, et al. "Universal and transferable adversarial attacks on aligned language models." arXiv preprint arXiv:2307.15043 (2023). ↩
-
https://github.com/leondz/garak ↩
-
https://docs.giskard.ai/en/latest/getting_started/index.html ↩
-
https://owasp.org/www-project-top-10-for-large-language-model-applications/ ↩
-
https://github.com/explodinggradients/ragas/blob/v0.1.7/src/ragas/metrics/_answer_relevance.py ↩
-
Raffel, Colin, et al. "Exploring the limits of transfer learning with a unified text-to-text transformer." Journal of machine learning research 21.140 (2020): 1-67. ↩
-
Retrieved from: https://github.com/explodinggradients/ragas/blob/v0.1.7/src/ragas/metrics/_context_recall.py ↩
-
Retrieved from: https://github.com/explodinggradients/ragas/blob/v0.1.7/src/ragas/metrics/_context_relevancy.py ↩
-
Retrieved from: https://github.com/explodinggradients/ragas/blob/v0.1.7/src/ragas/metrics/_context_precision.py ↩