Experiments and Insights on Improving RAG Pipelines for Real Datasets
To demonstrate some of the concepts in the previous section, we built RAG pipelines for possible use cases in the Singapore government and ran experiments to assess how modifying pipeline components influences performance. We emphasize that the improvements to RAG pipelines we have discussed are not a panacea, and highly dependent on the objectives and expected outcomes of individual use cases. The following experiments are expressly to show the reader, given specific use cases, how we build, iterate and evaluate our pipelines - the conclusions here should not be taken to mean that certain techniques are always better than others, because what works for one dataset may not necessarily work for another.
In addition to evaluating different custom pipeline components, we also compare our basic pipeline with basic pipelines in Amazon Bedrock1 and Vertex AI Agent Builder2. Both of these managed services 3 provide options for building RAG pipelines end-to-end with minimal effort. In other words, both provide the tools for automated preprocessing, chunking, indexing, retrieval and completion. This is to provide users with a comparison between few-click solutions and custom solutions; depending on the desired use case, these managed services offer a strong value proposition because they are easy to deploy. We used the default indexing and retrieval options for both Bedrock and Vertex AI.
Although several benchmarking datasets like MS MARCO, MMLU and TruthfulQA already exist, we did not use them for several reasons:
- Experiment results on these datasets are widely published, so repeating similar experiments and finding similar results would not be of much value.
- These datasets are curated and validated with substantial manual involvement and, hence, not representative of real world datasets. We do not expect the reader to be able to obtain such high quality datasets for their own experiments if they were to replicate our approach.
- These datasets are too generic and not focused on specific use cases in government.
Datasets
Knowledge Base 1 - Hansard4
This knowledge base consists of speeches and debates made in Parliament and provides a record of parliamentary business and proceedings each session. Each record is usually recorded as verbatim as possible. Public service officers often use this knowledge base to obtain information about key issues discussed in parliament. For instance, officers might query Hansard to draft replies to parliamentary questions by taking reference from past replies on similar issues.
Knowledge Base 2 - Judiciary5
This knowledge base consists of written judgements of cases heard in the Singapore courts and selected case summaries of these decisions. Users, such as members of the legal service, may query it to find out past judgements for certain offences or details of previous cases.
Evaluation Dataset Generation
For both our datasets, we only used data from 2022 onwards. As we do not have a sizeable dataset of real user questions with validated, human generated answers, we created synthetic evaluation datasets for each knowledge base. Each entry in the evaluation datasets has the following:
- Question
- Answer
- Relevant Chunks - information used to generate the question answer pairs
The following diagram shows how the reference datasets were generated:
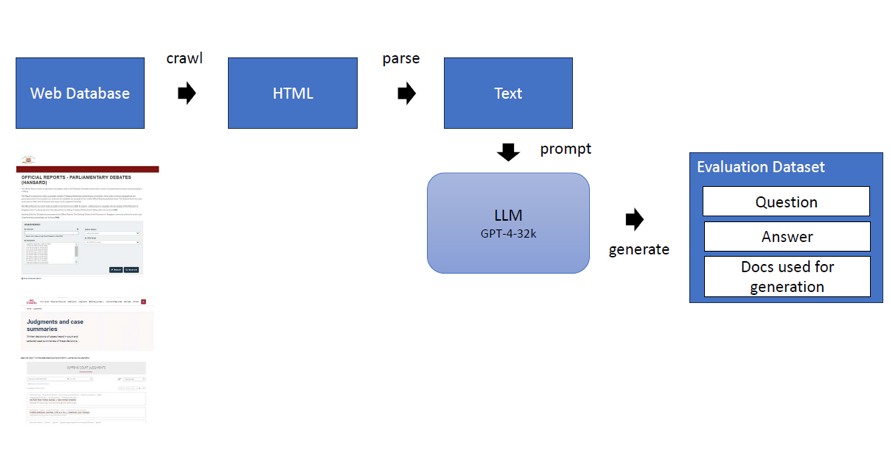
We obtained 197 question-answer pairs for the Hansard dataset and 270 question answer pairs for the Judiciary dataset. A detailed explanation of how we obtained our datasets can be found in the Annex.
Base RAG Pipeline
For each knowledge base, we built a base RAG pipeline as follows, using Langchain:
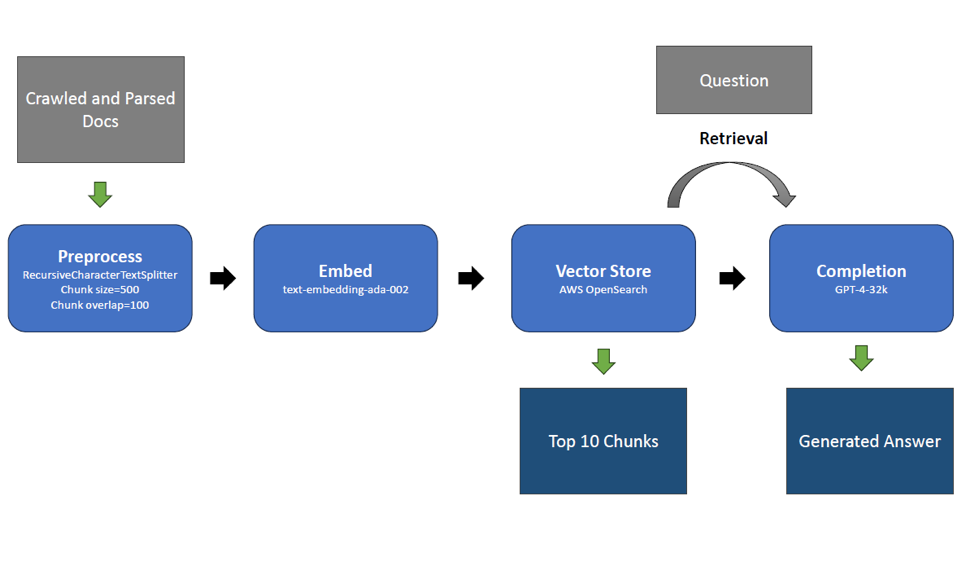
The base pipeline uses the following components and settings:
- Parser: Not required as the documents have already been crawled in text format
- Chunking: Documents are chunked using Langchain RecursiveCharacterTextSplitter with chunk_size=500 and chunk_overlap=100 tokens
- Embedding: Azure Open AI’s text-embedding-ada-002 is used to embed the chunks
- Vector Store: AWS OpenSearch is used to store the chunks and embeddings for retrieval, using semantic search. For retrieval, the top 10 documents included as context in the LLM prompt.
- Completion: Azure Open AI’s GPT-4-32k is used as the completion model
Variations
We varied components of the base RAG pipeline, one at a time, using some of the aforementioned techniques (here), to assess how performance is affected. Most of the techniques we selected are generally applicable to all datasets, should the reader want to follow our approach and try the same techniques. For those techniques which require additional inputs or processing, we share our approach on getting them.
We opted to vary components one at a time for simplicity in experimentation, since this allows us to compare components in isolation with the baseline. Because we are experimenting with components across the entire RAG pipeline, testing every possible combination of components quickly becomes untenable as the list of options increases.
Preprocessing
Preprocessing text data prior to indexing entails the removal of unnecessary information that might obscure relevant information, inflate memory usage or lead to higher token costs. In the context of Hansard documents, we observed that:
- Every document begins with a summary paragraph of questions asked by MPs before the actual transcription of the minister’s reply. Often, these paragraphs did not contain much information about actual policy.
- Some documents end with footnotes that do not offer useful information.
One hypothesis was that the summary paragraph, being questions as well, are semantically similar to our queries but may not carry useful information, causing them to crowd out more useful chunks during retrieval. We hence removed these summary paragraphs and footnotes before indexing the Hansard document for our preprocessing experiment run.

Retriever
Hybrid Search
Our hybrid keyword-semantic search engine makes use of the normalisation pipeline on OpenSearch, as described here, to normalise the scores of the BM25 keyword search results and that of the semantic search results. The search results are then reranked using the normalised scores to get the top 10 documents. The normalisation pipeline used is shown below:
PUT /_search/pipeline/norm-pipeline
{
"description": "Post-processor for hybrid search",
"phase_results_processors": [
{
"normalization-processor": {
"normalization": {
"technique": "l2"
},
"combination": {
"technique": "arithmetic_mean"
}
}
}
]
}
Note that there are many different ways to implement hybrid search and this is only one of the ways to do so.
Cross-Encoder Reranking
Instead of taking just the top 10 documents from semantic search, we retrieved the top 50 documents for the query, and used Cohere’s Rerank API6 endpoint with the model rerank-english-v2.0 to rerank them. Following that, we used the top 10 reranked documents as the context.
HyDE
Instead of using the embedding of the question for retrieval, we used GPT-4-32k to create a hypothetical answer to the question, and used the embedding of the passage to find the relevant documents. We used the following prompt to generate the hypothetical document answer:
Recursive Retrieval
To perform recursive retrieval, we created a first-stage index with embeddings of document titles7 and a second-stage index with embeddings of actual document chunks. At query time, we query the first-stage index to get N most relevant documents, and then query each of those N documents to obtain the M most relevant chunks in each document. Given a query for K documents, we then sort all N*M documents and return the top K in terms of relevance scores8.
Fine-tuned Embeddings
We replaced the text-embedding-ada–002 model with a fine-tuned BAAI/bge-large-en-v1.5 embedding model. The steps to finetune the model are as follows, taking reference from this guide:
- Use an LLM (we used Mistral-Instruct-7B-v0.2 for speed and cost efficiency) to generate a list of questions for each chunk in the knowledge base. The prompt used to generate the questions is also a simple one:
- Compile a list of (question, positive chunk, negative chunk) triples where the positive chunk is the chunk used to generate the question and a negative chunk is a random sample from all other chunks.
- Use the hard negatives miner from FlagEmbedding to convert the negative chunks into “hard negatives”. This pools all the negative chunks together and uses the pretrained BAAI model to embed them. After which, the chunk that has the largest distance from the question embedding is chosen as a “hard negative” which is most dissimilar to the question (based on the pretrained model’s embeddings).
- Finetune the pretrained model using the list of (question, positive chunk, negative chunk) triples using FlagEmbeddding’s finetuning script.
- Merge the fine-tuned model with the pretrained model with equal weightage using LM Cocktail so that the embedding model is not overfitted to the fine tuning data, and can still be used for other data.
Altogether, we generated 29312 triples for Hansard and 35383 triples for the judiciary dataset, which we used to finetune two separate embedding models with the following settings:
learning_rate 1e-5
fp16
num_train_epochs 10
per_device_train_batch_size 16
dataloader_drop_last True
normalized True
temperature 0.02
query_max_len 64
passage_max_len 500
train_group_size 2
negatives_cross_device
The fine-tuned model was then used to embed the original datasets and the resulting embeddings with their chunks were stored in a separate index for retrieval.
Completion
Lost-in-the-Middle Reranking
Liu et al. published a paper9 showing that LLMs give more attention to content at the beginning and end of the provided contexts, and less attention to the content in the middle. One way to circumvent this is to rearrange the top ranked documents to the start and the end when we are concatenating the documents to form the context. We applied this rearrangement to the context before passing it to the LLM to assess any change in performance.
Mistral-Instruct-7B-v0.2
We also tested a different LLM to see how the quality of answers differs from that of GPT-4-32k, given the same question and context. Mistral-Instruct-7B-v0.2 was chosen for its speed (because of its smaller size), relatively good performance (according to the LLM leaderboard), and similar context length as GPT-4-32k. The model was hosted on our own DGX server using one A100 80GB GPU.
Evaluation Metrics
Retriever Evaluation Metrics
Mean Average Precision (MAP)
Each question-answer pair in the Hansard dataset was generated using multiple chunks across multiple documents. We consider the chunks which were used to generate the pair as relevant, and all other chunks to be non-relevant. Since, each question-answer pair has multiple relevant chunks, we use the Mean Average Precision (MAP@10) to measure the quality of the search results.
Mean Reciprocal Rank (MRR)
For the judiciary dataset, each question-answer pair was generated from a single document. We consider the documents which were used to generate the pair as relevant, and all other documents to be non-relevant. Since each question-answer pair has only a single relevant document, we use the Mean Reciprocal Rank (MRR@10) to measure the quality of the search results.
Completion Evaluation Metrics
Ragas Answer Correctness
For most government use cases, wrong or misinformed answers from an RAG system can be costly to both the government and members of the public. With this in mind, we assessed RAG outputs using Ragas’ Answer Correctness. This approach relies on an LLM (we used GPT-4-32k) to compare the generated answer with the reference answer, and extract the True Positives, False Positives, and False Negatives. The counts of each are then used to calculate the F1 score, which determines the Answer Correctness.
Results
In the following section, we present the results from our experiments. Each version of the pipeline tested varies a single component from the baseline to enable a more interpretable comparison.
Hansard
Retriever Modifications
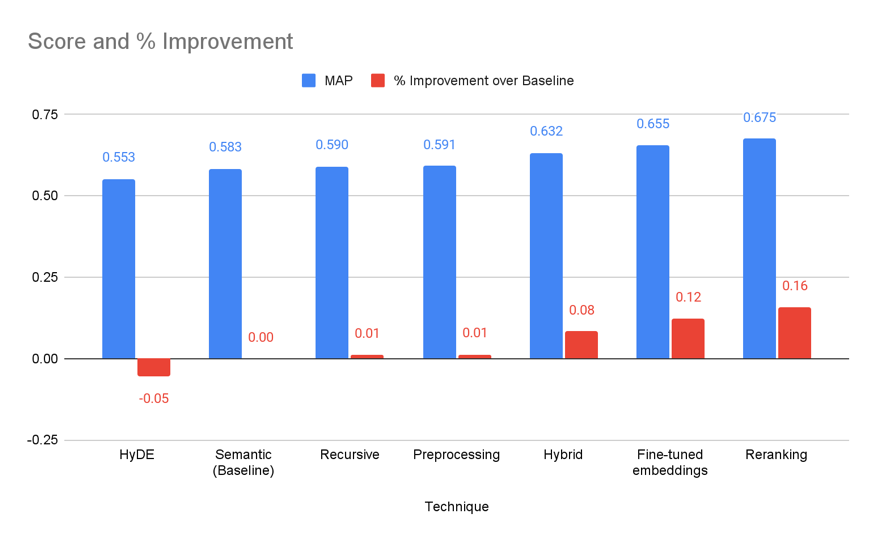
The results above show that, with the exception of HyDE, all the techniques improved the retriever’s MAP results. Cross-Encoder reranking and fine-tuned embeddings’ improvements are the most significant, at 16% and 12%, respectively.
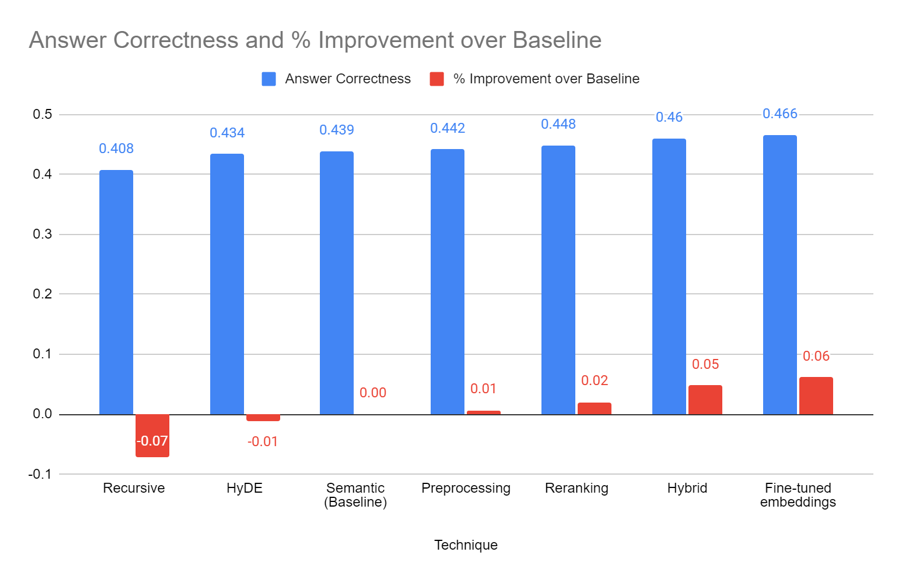
Compared to the retrieval scores, the improvements to answer correctness shown above are less significant, with fine-tuned embeddings context generating the best improvement of only 6% over the baseline. Another observation is that the retriever with the most relevant search results (cross-encoder reranking) does not necessarily have the best answer correctness scores. This demonstrates the importance of evaluating a model at multiple points using different metrics.
One possible reason for the disjunct between retriever relevancy and answer correctness is that, even though the retriever might be able to find more relevant chunks, the model still has to extract correct information from each chunk to answer the question. This can be affected by many variables, such as the way the questions and documents are phrased, resulting in lower-than-expected model performance improvements despite having more relevant information. However, it is useful to note that the top three retriever improvement techniques all led to improvements in the answer correctness, and all of them are good candidates for improving the retriever pipeline.
Completion Modifications
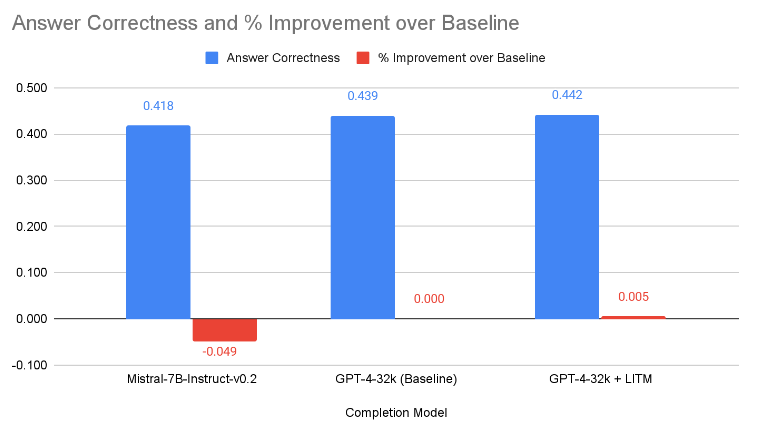
The diagram above shows the effect of changing the completion model. When Lost-In-The-Middle reranking was applied, there is a rather insignificant improvement of the answer correctness by 0.5%. Using Mistral-7B-Instruct-v0.2 led to an almost 5% decrease in the answer correctness scores. However, for use cases where there are constraints like not being able to send classified data over the internet, using Mistral-7B-Instruct-v0.2 is a viable option, if the performance degradation can be tolerated.
Taking into account all the experiment results, we used fine-tuned embeddings for our retriever, then applied lost-in-the-middle reranking of the results, before feeding the reranked context into a GPT-4-32k model.
Comparison with CSP Options
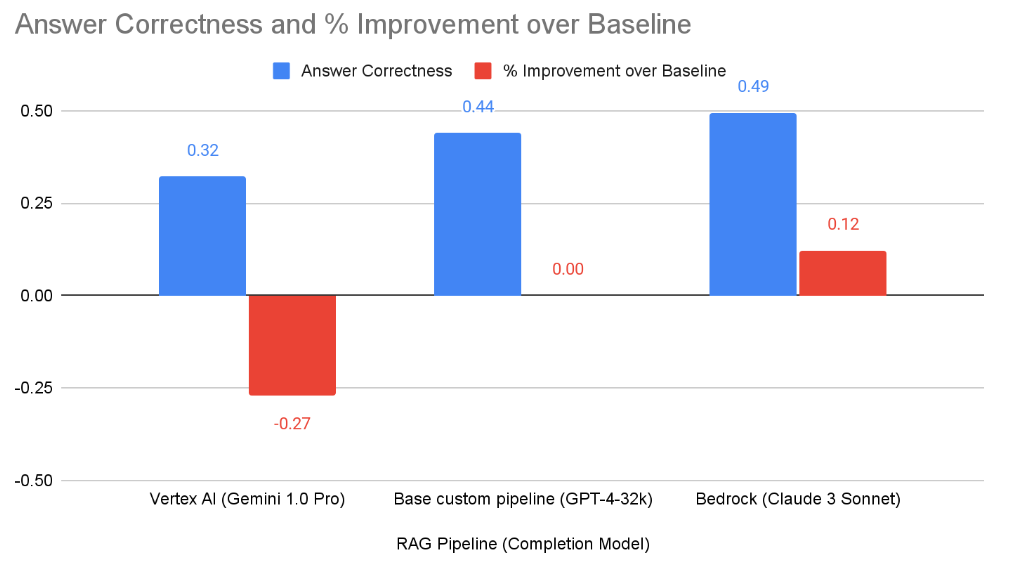
Bedrock outperforms the custom pipeline by a substantial margin of 12%, whereas Vertex AI performed 27% worse. In the case of the Hansard dataset, there appears to be a strong case for using Bedrock, particularly since Hansard is available to the public and therefore has no constraints on confidentiality10. However, we emphasise that these findings do not mean that CSPs options are necessarily better or worse than a custom pipeline. Instead they provide additional viable options, depending on the parameters of a project.
Judiciary
Retriever Modifications
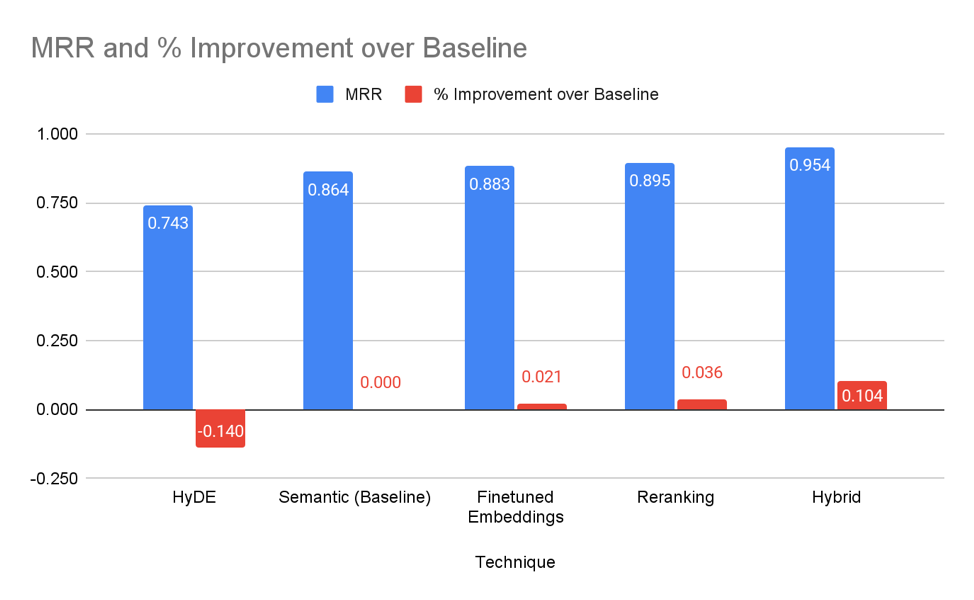
We performed the same experiments on the Judiciary dataset and the outcomes are similar, with recursive retrieval, fine-tuned embeddings, reranking and hybrid search showing improvements in retriever accuracy. Note that preprocessing was not a category of its own because the judiciary data did not require any obvious changes.
Particularly noteworthy here is that hybrid search yielded a much larger improvement than other methods. This is likely because judiciary documents are much more likely to contain unique keywords (such as the case name, offence, people or organisations) than the Hansard dataset, making them more likely to benefit from a combination of semantic and keyword search. Hybrid search, which combines both semantic and keyword search, performs particularly well on datasets like this.
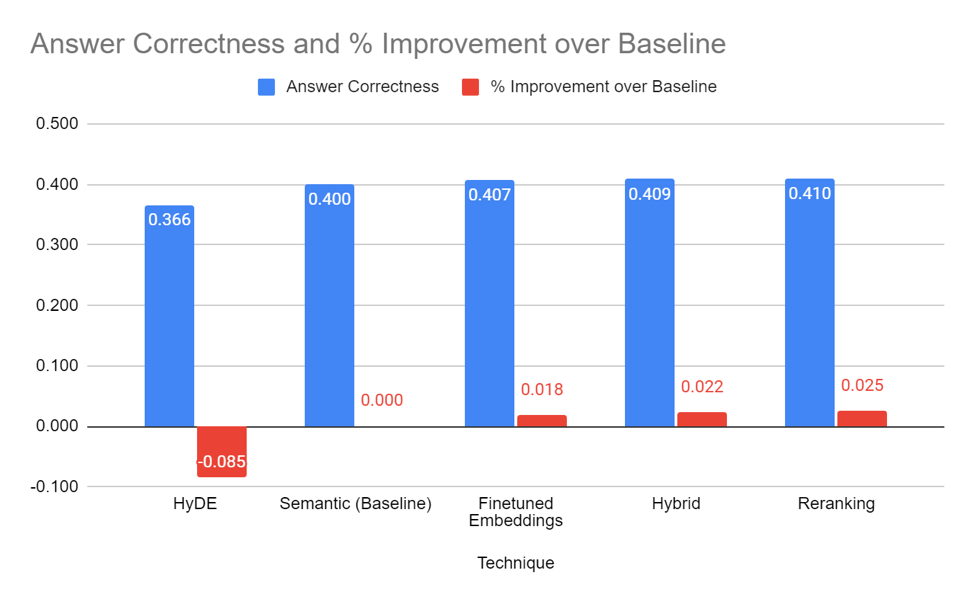
Similar to the Hansard dataset, we see that the magnitude of improvement for answer correctness is lower than that for the retriever. We hypothesise that this occurs for similar reasons as well - the LLM still needs to sift out the relevant information from the retrieved documents to synthesise a meaningful and correct response.
Legal documents also present a slightly different problem dynamic than Hansard - whereas Hansard questions require reference to multiple (usually) shorter documents written in plain English, judiciary questions require reference to single documents written in less accessible legal jargon. Even when presented with the right document, the LLM might lack sufficient semantic complexity to deal with long and complex legal writing.
Completion Modifications
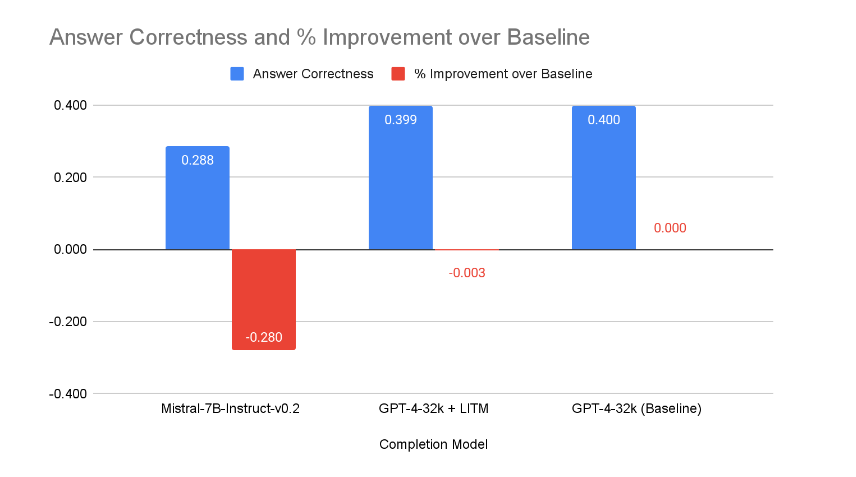
The graph above shows that our default pipeline using GPT-4-32k has the best performance and Lost-In-The-Middle reranking has virtually no impact. Mistral-7B-Instruct-v0.2 provides significantly poorer performance - one possible reason might be the increased complexity of language in the judiciary dataset discussed earlier, which a smaller model like Mistral-7B might have difficulty comprehending. In specialised domains like the legal sector, it is likely that larger or fine-tuned LLMs are the better choice for completion.
Taking into account the results for the judiciary dataset, we used recursive retrieval for our retriever and fed the context into a GPT-4-32k model without doing lost-in-the-middle reranking.
Comparison with CSP Options
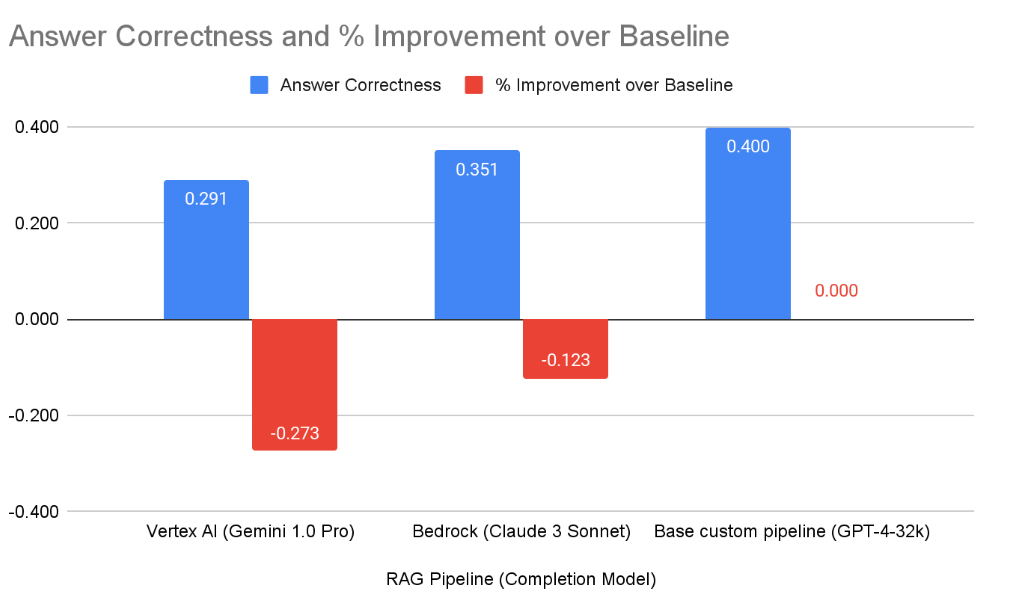
The results above demonstrate the drawbacks of fully end-to-end solutions11 - while they sometimes work well, other use cases may require a custom pipeline for better performance. Bedrock worked particularly well in the Hansard case but saw a 12% reduction in answer correctness here, whereas Vertex AI performed poorly in both instances with a 27% reduction in answer correctness12. Once again, we encourage readers to perform their own experiments for their specific use cases and to use this playbook as a springboard for ideas.
Latency
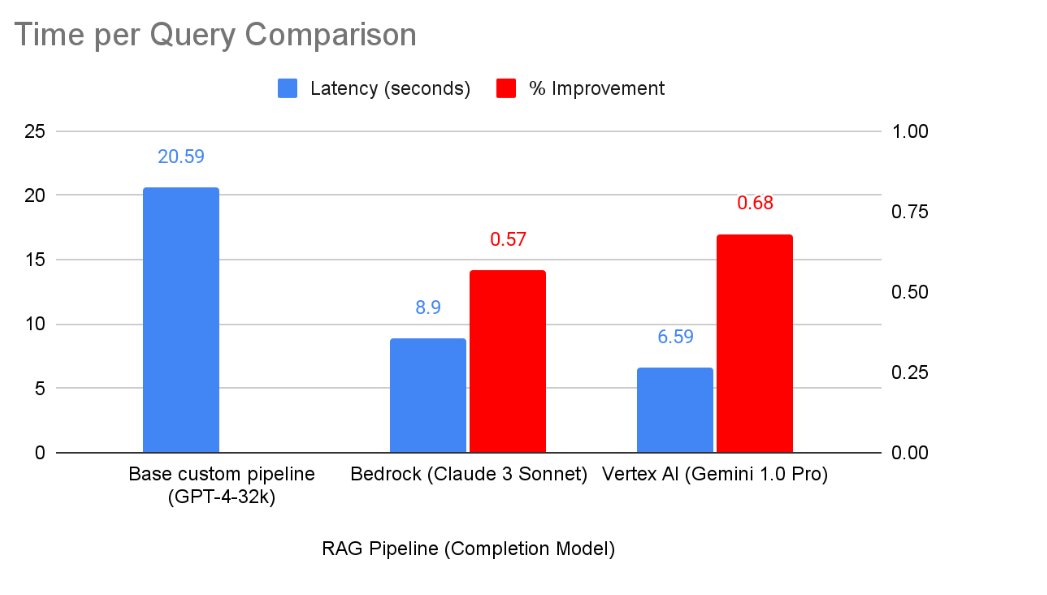
Performance considerations aside, there are also other considerations for an effective RAG system that is ready for deployment. One key aspect is latency - put simply, waiting a long time for a query makes for poor UX, no matter how good the answer is. Ideally, a RAG system strikes a balance between accuracy and latency. For directness, we look at the average time taken per query as a benchmark, based on questions from the Hansard dataset13. As we can see below, Bedrock is 57% faster and Vertex AI 68% faster than our baseline RAG configuration. This is a function of slightly faster retrieval and significantly faster LLM completion14.
-
Our stock Amazon Bedrock RAG uses Cohere Embed English V3 for embeddings alongside Claude 3 Sonnet for completion. For other options, see https://docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base-supported.html ↩
-
At the time of our experiments in Apr 2024, Bedrock Knowledge Base is only available in some regions, not including Singapore. ↩
-
At the time of our experiments in Apr 2024, Vertex AI Agent Builder is in public preview. See https://cloud.google.com/blog/products/ai-machine-learning/build-generative-ai-experiences-with-vertex-ai-agent-builder ↩
-
https://sprs.parl.gov.sg/search/#/home ↩
-
https://www.judiciary.gov.sg/judgments/judgments-case-summaries ↩
-
Note that Cohere Rerank is a proprietary model and, as such, the model architecture used for reranking is not publicly known. ↩
-
Again, for resource efficiency. An alternative approach would be to embed document summaries in the first-stage index rather than document titles. ↩
-
LlamaIndex provides its own abstraction for recursive retrieval based on IndexNodes. However, we find that LlamaIndex performs extensive pre and post-processing of contexts and, as such, does not return the individual source nodes. This makes evaluation of the retriever impossible, so we used a simple custom implementation of recursive retrieval. For simpler use cases, LlamaIndex may be a good out-of-the-box option, but for more specific use cases, customizing LlamaIndex or building your own recursive retriever may be better. ↩
-
https://arxiv.org/abs/2307.03172 ↩
-
Further experimentation reveals that the performance improvement is both from better answer correctness from retrieval and completion. Two additional configurations, Bedrock’s retriever + GPT-4-32k and Opensearch + Bedrock’s Claude 3 Sonnet each yielded a 7.5% improvement in answer correctness. The default Bedrock pipeline combines both of these to yield the best results. ↩
-
It is worth noting that while managed services provide an end-to-end solution, if a custom pipeline is required then they do allow some flexibility. For instance, Bedrock can be used just for its high availability of foundation models like Claude 3 Sonnet and complemented with an OpenSearch index based on a custom indexing routine. Similarly, Vertex AI can be used just for its retriever and paired with a different completion model. ↩
-
Further experimentation reveals that the performance degradation in VertexAI was mostly due to Gemini 1.0 Pro. When pairing the Vertex AI retriever alongside Claude 3 Sonnet, we obtained results similar to Bedrock. With the release of Gemini 1.5 Pro, Vertex AI may soon offer comparable performance in their end-to-end RAG. ↩
-
Other measures of latency are “time per output token” (TPOT) and “time to first token” (TTFT). We opt for the average time per query because 1) TTFT is relevant only if we are streaming responses 2) Time per query is grounded in our question-answering use case because it includes retrieval. ↩
-
Note that Gemini 1.0 Pro and Claude 3 Sonnet are likely much smaller than GPT-4; however, a larger model does not always mean better performance, as our experiment results demonstrate. ↩