Improving RAG Pipelines
An RAG pipeline comprises multiple components which serve to combine the information from a domain-specific knowledge base with the semantic depth of LLMs. Each of these components can be tuned to improve RAG performance. This section provides an overview of possible enhancements that can be made to a basic RAG pipeline, arranged in ascending order of technical complexity and computational cost. Importantly, it must be noted that these enhancements are not universally applicable across all RAG use cases. As emphasized in the literature, improvements to RAG pipelines, and LLMs more broadly, are inherently task-specific and should be tailored to the objectives and expected outcomes of individual use cases.
The following is a summary table of the RAG improvement techniques covered, along with the corresponding pipeline component they affect and relevant evaluation metrics:
| RAG Pipeline Component | Improvement Techniques | Evaluation Metric |
|---|---|---|
| Data Preparation | Text preprocessing Chunking Strategy |
- |
| Embedding | Embedding Fine-tuning | - |
| Indexing | - | - |
| Retrieval | Retrieval Optimization Query Enhancement Reranking |
HIT@K MRR@K MAP@K NDCG@K Ragas context relevancy, precision, recall |
| Completion | Prompt Engineering LLM Fine-tuning |
Ragas answer relevancy AutoAIS ROUGE BLEU METEOR F1 Score BERTScore UniEval G-Eval |
Techniques to Improve RAG Pipelines
Prompt Engineering:
Complexity: Low
Background: Engineering the right prompts - effectively giving an LLM pointers on how to respond - is an accessible, zero-code way to refine LLM responses at inference without the need for model retraining. For simpler use cases, prompt engineering may prove sufficient in achieving the desired level of LLM performance. Crucially, prompt engineering is also inherently multi-task, since different prompts can be engineered for different tasks without needing to alter the LLM. However, prompt engineering cannot fundamentally introduce new information to a model's existing knowledge base, is ill-suited to teaching LLMs to replicate complex styles and, depending on the complexity of prompts, may lead to significantly higher token consumption.
Methods:
Zero-Shot
Zero-shot prompting tells an LLM what to do but does not provide examples. For instance, the question “Name me the capital of France.”
Few-Shot
Few-shot prompting tells an LLM what to do and provides examples of what ideal responses look like. For instance, “Berlin is the capital of Germany. Kuala Lumpur is the capital of Malaysia. Name me the capital of France”
Chain of Thought Reasoning
Chain of Thought prompting tells an LLM what to do and provides logical steps to reach that answer. For instance1:
“The odd numbers in this group add up to an even number: 16, 11, 14, 4, 8, 13, 24. A: Adding all the odd numbers (11, 13) gives 24. The answer is True.
The odd numbers in this group add up to an even number: 17, 9, 10, 12, 13, 4, 2. A: Adding all the odd numbers (17, 9, 13) gives 39. The answer is False.
The odd numbers in this group add up to an even number: 15, 32, 5, 13, 82, 7, 1. A: ____”
Text Preprocessing
Complexity: Low
Background: RAG pipelines exhibit optimal performance when text undergoes thorough preprocessing prior to indexing into a vector database. Removing unnecessary tokens and, particularly for longer documents, segmenting text into more semantically coherent chunks directly influences the quality of text embeddings and semantic search. Being attentive to the right preprocessing techniques hence has a direct impact on RAG pipeline performance.
Data Cleaning
Text data is unstructured and often contains redundant or unnecessary information that detracts from the downstream task for which an RAG pipeline is intended. For example, documents scraped from websites could contain html tags or copyright signatures that are uninformative about the actual content on the website. At best, these artificially inflate computational costs from document embeddings and LLM input tokens without impacting performance. At worst, they compromise RAG performance by causing less semantically coherent text chunking or by crowding out more relevant documents during retrieval. In general, it is best-practice to thoroughly clean documents before they are indexed into an RAG system.
Chunk and overlap size234
While it is possible to obtain an embedding for a document as long as it fits into the embedding model’s context length, embedding an entire document is not always an optimal strategy. It is common to segment documents into chunks and to specify an overlap size between chunks. Both of these parameters can help to facilitate the flow of context from one chunk to another, and the optimal chunk and overlap size to use is corpus specific. Embedding a single sentence focuses on its specific meaning but forgoes the broader context in the surrounding text. Embedding an entire body of text focuses on the overall meaning but may dilute the significance of individual sentences or phrases. Generally, longer and more complex queries benefit from smaller chunk sizes while shorter and simpler queries may not require chunking.
Methods:
Fixed character/token splitting
- Naively split based on fixed character/token counts
- Might cut off words
Sentence Splitting
- Split into one or more sentences. Better than character/token splitting at preserving semantic structure.
Recursive Splitting
- Given a fixed chunk size, recursively split on a list of separators until the chunk size is fulfilled.
- Typically, [‘\n\n’, ‘\n’, ‘ ‘] is a common choice for separators, since this splits based on paragraphs then sentences and is more likely to preserve semantic structure
Splitting with added context
- Split into chunks but include added context in chunks. Some approaches are to pass a running summary from previous windows or to create links to surrounding text. See Recursive/Staged Retrieval
Reranking
Complexity: Low
Background: RAG pipelines utilize semantic search to return a subset of relevant documents, but limitations in embedding quality could mean that the most relevant documents do not come first. Reranking can be used to improve LLM responses by reordering and filtering semantic search results to provide LLMs with only the most relevant documents to a query. Integrations for common out-of-the-box reranking services like Cohere into LangChain and LlamaIndex make reranking easily implementable in RAG pipelines.
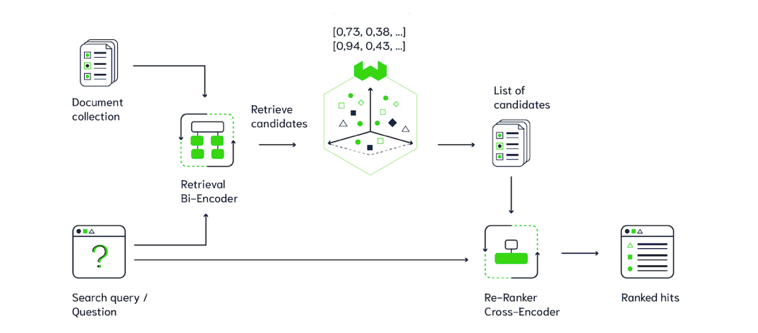
Methods:
Cross-Encoder567
In general, finding the most similar documents to a query is a sequence-to-scalar task that can be modeled in two ways:
- In the bi-encoder approach, a siamese transformer architecture takes query-document pairs, encodes them independently then outputs similarity
- In the cross-encoder approach, a single transformer architecture takes query-document pairs and outputs similarity.
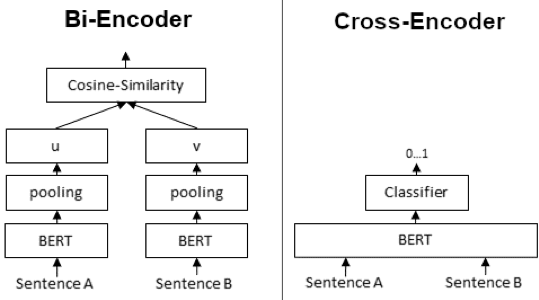
While cross-encoders usually have better performance than bi-encoders by modeling richer query-document interactions, they are computationally more expensive, particular at inference. Assuming we have D documents and Q queries:
- The bi-encoder approach requires D+Q model calls to create embeddings because the query and document encoders can be used separately, followed by D*Q vector similarity calculations
- The cross-encoder approach requires D*Q model calls to calculate every pairwise similarity
Crucially, the individual encoders of the bi-encoder can be used separately, meaning that document embeddings can be created and stored in the vector database before inference - at inference, only the query embedding has to be obtained. Because the cross-encoder must always take query-document pairs as input, semantic search using the cross-encoder quickly becomes intractable given a large corpus of documents. As a result, bi-encoders are better suited for embedding documents and queries for semantic search, while cross-encoders can be used for re-ranking a smaller subset of candidate documents obtained from semantic search at inference.
Optimizing Document Retrieval
Complexity: Medium
Background: RAG pipelines should retrieve only the most relevant information for the generative model to provide a response, both from a cost and performance perspective8. How we structure and query the document store hence has a direct impact on the LLM through the relevance of retrieved information. These methods revolve around retrieving the best possible information to answer a given query.
Recursive Retrieval9
In situations where basic text preprocessing is insufficient to segment a document into semantically coherent chunks, recursive retrieval offers a solution by introducing stages to information retrieval. With long and complex documents, for example, document-level summaries can be indexed in an overall vector database with each node linking to a separate index for document-specific chunks. This approach decouples chunk retrieval from response synthesis, as the embedding required for information retrieval may differ from the content necessary for question answering.
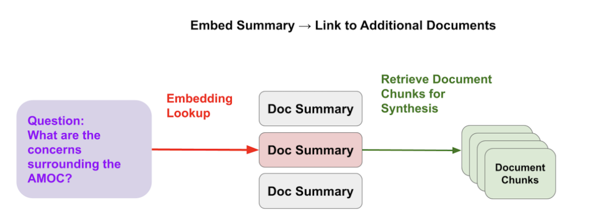
Methods:
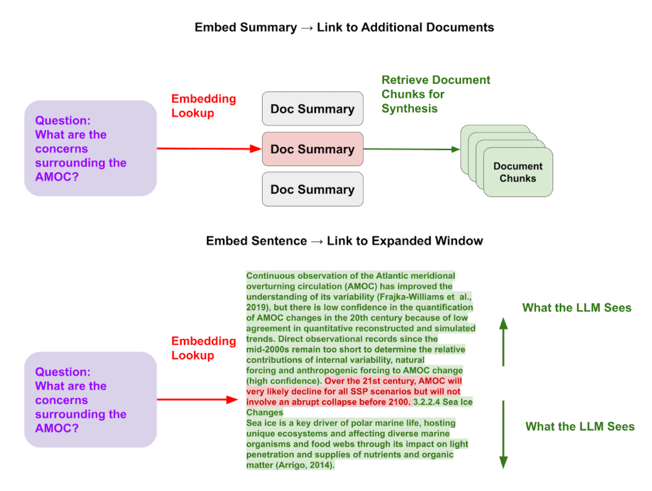
Document Summary1011
- Documents are stored in a hierarchical relationship, with overall document summaries embedded first and linked to document specific chunks
Sentence Window12
- Sentences are embedded with a window, so semantic search is performed using sentence embeddings but surrounding sentences are retrieved together with the target sentence
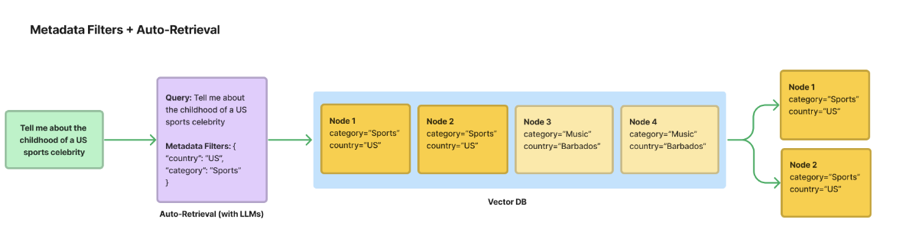
Metadata Filtering13
- The simplest form of recursive retrieval, where metadata filters are applied before or after semantic search is performed
Query Routing/Classification14
Queries can also be directed to a subset of indexes based on some classification procedure. For example, different databases might contain different corpora - one might embed individual documents directly to answer specific questions (“How many X incidents happened in 2023”) while another embeds groups of documents to answer high-level questions (“Give me a high-level summary on the topic of X”). Classification steps can be rules-based or model-based, using an auxiliary LLM or trained classification model.
Hybrid Search / Ensemble Retrieval15
Hybrid search combines sparse retrievers (e.g. BM25) and dense retrievers (e.g. embedding distance) to perform keyword and semantic search together. This might be particularly relevant in fields such as medicine or finance, where specific keywords remain extremely informative in information retrieval.
Query Enhancement
Complexity: Medium
Background: Where database optimization focuses on improving document retrieval given a specific query, query enhancement focuses on enhancing a query to improve search coverage and increase the likelihood of relevant documents being returned.
Methods:
Query expansion161718
Complex queries can be broken down into subqueries or spin-off queries can be generated from the original query to expand search coverage. In multi-query retrieval systems, there is typically an additional step to amalgamate results from each sub-query and re-rank them for LLM consumption. In a multimodal model setting, this might work well to retrieve data from different databases
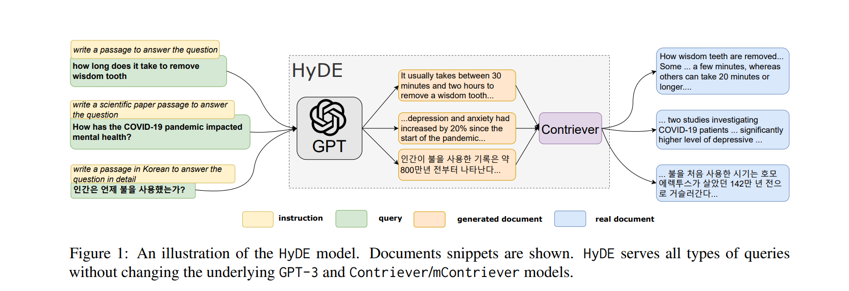
Hypothetical document embeddings (HyDE)1920
Semantic search engines work by identifying documents whose embeddings are closest to query embeddings, but query and document embeddings may not necessarily be similar. HyDE addresses this by generating a hypothetical document and using both the query and hypothetical document to perform embedding comparisons. Ideally, the hypothetical document improves search results by being semantically more similar to relevant documents than the query. In practice, HyDE can generated multiple documents and average the embeddings across the documents + query21.
Prompt Compression222324
Unlike query expansion and HyDE, which improve performance at the expense of longer queries, prompt compression aims to improve performance while reducing query size to overcome ‘lost-in-the-middle’ problems. ‘Lost-in-the-middle’ refers to the phenomenon where LLMs, when dealing with long prompts, perform best when relevant information is at the beginning or end of the prompt and worst when it is in the middle of the prompt. Several algorithms for prompt compression exist:
- LangChain DocumentCompressor: Uses either additional LLM call to extract only key statements from documents relevant to the query or uses embedding distance to filter out irrelevant chunks in a document25
- LLMLingua and LongLLMLingua: Recent work by Microsoft Research which works by passing the original prompt (prompt, documents, question) through a multi-stage process that compresses the prompt using a smaller LM, performs retrieval, then rebuilds the final response for human interpretability. Compression is done algorithmically by estimating document and token relevance using the small LM.
Fine-tuning
Complexity: High
Background: Fine-tuning is a computationally intensive undertaking which involves further training a pre-trained model with new data to improve performance on a specific downstream task or new domain.
Methods discussed above focus on improving the quality of inputs to the LLM in an RAG pipeline (e.g. improving instruction quality through prompt engineering or providing more relevant context through retrieval optimization), but they do not fundamentally alter an LLM’s inherent knowledge or semantic depth. Hence, despite its high computational costs, fine-tuning can be a viable solution if an LLM needs to be fundamentally adapted to a new task which it is unfamiliar with. While the upfront costs of fine-tuning are significantly higher than other methods, successful fine-tuning could lead to superior performance and costs can be amortised over the lifetime of the model.
Fine-tuning can be applied to either LLM embeddings or LLM models, each with different implications for an RAG pipeline.
Methods:
Embedding Fine-tuning
Embeddings are low-dimensional, continuous vector representations for words, sentences or documents that are optimised so that similar instances fall close to one another. In a RAG setting, this means that the embedding of a given query should be close to the embeddings of the documents most relevant to that query, allowing them to be retrieved at query-time. While pre-trained embedding models may be used to achieve this, query-document embedding similarity is not guaranteed since these models are usually optimised across a suite of natural language tasks. In such cases, embeddings become a bottleneck on RAG performance and enhancements like document reranking are unlikely to help because, fundamentally, relevant documents are not being retrieved in the first place. In these situations, embedding fine-tuning could improve performance. Importantly, this requires a labelled dataset of query-document pairs to further train a pre-trained embedding model.
Model Fine-tuning2627
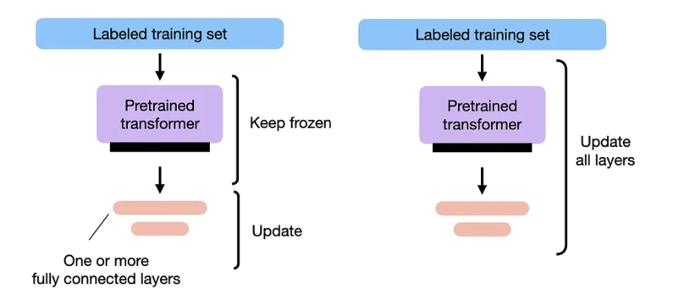
While embedding fine-tuning focuses on improving the quality of inputs to an LLM, model fine-tuning focuses on improving the quality of outputs from the LLM. Pre-trained models often have strong general language understanding making them capable of in-context learning - supplying an LLM with a well-engineered prompt is often sufficient to elicit a desirable response without additional training. However, LLMs may not be well-adapted to specific tasks or present unexpected and unintended behaviour like hallucination. While prompt engineering can help to refine LLM outputs, it may be insufficient to fundamentally alter an LLM.
Like fine-tuning an embedding model, fine-tuning an LLM requires a labelled dataset for a specific downstream task. Because fine-tuning an LLM is computationally intensive, recent methods have focused on parameter efficient fine-tuning (PEFT), which tune a subset of model weights. In practice, there are multiple approaches to PEFT - prompt tuning methods focus on tuning embedding inputs to LLM28 while other methods focus on efficiently tuning selected hidden layers in a model.
More details of specific model fine-tuning methods can be found in the Annex.
-
Example from https://www.promptingguide.ai/techniques/cot ↩
-
https://www.pinecone.io/learn/chunking-strategies/ ↩
-
https://www.mattambrogi.com/posts/chunk-size-matters/ ↩
-
https://safjan.com/from-fixed-size-to-nlp-chunking-a-deep-dive-into-text-chunking-techniques/#from-fixed-size-to-nlp-chunking-a-deep-dive-into-text-chunking-techniques ↩
-
https://www.sbert.net/examples/applications/retrieve_rerank/README.html ↩
-
https://www.sbert.net/examples/applications/cross-encoder/README.html ↩
-
Siamese because weights are shared between encoders, at least in the original SBert architecture. The paper also explores triplet networks and loss. https://arxiv.org/pdf/1908.10084.pdf ↩
-
https://arxiv.org/abs/2307.03172 ↩
-
https://docs.llamaindex.ai/en/stable/optimizing/production_rag.html ↩
-
https://docs.llamaindex.ai/en/stable/examples/query_engine/pdf_tables/recursive_retriever.html ↩
-
https://docs.llamaindex.ai/en/stable/examples/index_structs/doc_summary/DocSummary.html ↩
-
https://docs.llamaindex.ai/en/stable/examples/node_postprocessor/MetadataReplacementDemo.html ↩
-
https://www.pinecone.io/learn/vector-search-filtering/ ↩
-
https://docs.llamaindex.ai/en/latest/examples/query_engine/RouterQueryEngine.html ↩
-
https://python.langchain.com/docs/modules/data_connection/retrievers/ensemble ↩
-
https://docs.llamaindex.ai/en/stable/examples/query_transformations/query_transform_cookbook.html#sub-questions ↩
-
https://docs.llamaindex.ai/en/latest/examples/query_engine/sub_question_query_engine.html ↩
-
https://python.langchain.com/docs/modules/data_connection/retrievers/MultiQueryRetriever ↩
-
https://python.langchain.com/docs/templates/hyde ↩
-
https://arxiv.org/pdf/2212.10496.pdf ↩
-
Line 21: https://github.com/texttron/hyde/blob/main/src/hyde/hyde.py ↩
-
https://github.com/microsoft/LLMLingua/blob/main/Transparency_FAQ.md ↩
-
https://arxiv.org/pdf/2310.05736.pdf ↩
-
https://arxiv.org/pdf/2310.06839.pdf ↩
-
https://blog.langchain.dev/improving-document-retrieval-with-contextual-compression/ ↩
-
https://magazine.sebastianraschka.com/p/finetuning-large-language-models ↩
-
In the Reinforcement Learning with Human Feedback (RLHF) paper, the authors point out that toxic and biased generations are an unintended behaviour that can be fine-tuned away. https://arxiv.org/pdf/2203.02155.pdf ↩
-
Note that this is different from tuning the embedding model directly. Prompt tuning augments input embeddings by adding trainable input layers; the embeddings themselves remain unchanged. ↩