Introduction
What is RAG?
Retrieval-Augmented Generation (RAG) is a framework in natural language processing (NLP) that combines techniques from both retrieval-based and generation-based approaches to improve the quality of text generation models. The primary idea behind RAG is to incorporate external knowledge sources, typically in the form of large-scale text corpora or databases, into the text generation process to augment the capabilities of generative models.
In RAG, the architecture consists of two main components:
-
Retrieval Component: This component is responsible for retrieving relevant information or context from a large external knowledge source based on an input query. This could involve retrieving passages, documents, or other relevant textual and non-textual data that can help inform the generative model’s response.
-
Generation Component: Once the relevant information is retrieved, it is used as input to a text generation model, typically a language model like GPT (Generative Pre-trained Transformer), to generate the desired output text. The role of the generative model is to extract and synthesise information in the context to provide a natural language response that is coherent and relevant to the input query.
By combining retrieval and generation components, RAG aims to leverage the benefits of both approaches. The retrieval component helps to provide context and relevant information to guide the generation process, while the generation component produces fluent and coherent text based on this information.
The diagram below demonstrates a typical flow for RAG.
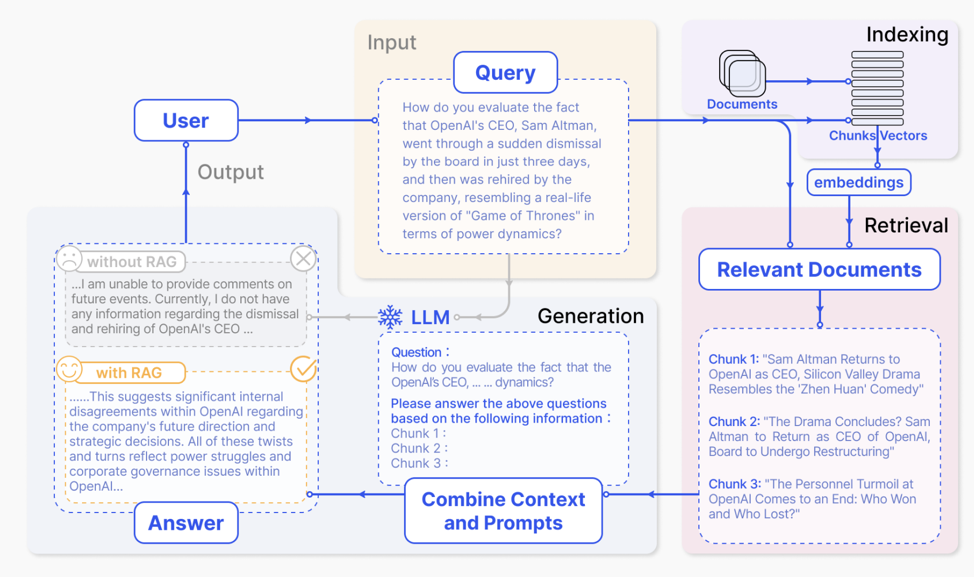
Ten Steps in Building an RAG System:
Supplementing the diagram above, we distil 10 steps in a typical RAG workflow. In later sections, we dive into each component in greater detail.
- Define the knowledge domain and gather relevant documents or data sources.
- Preprocess the documents (e.g., cleaning, splitting into chunks).
- Create a vector index from the document chunks using an embedding model.
- Set up the retrieval component to query the vector index and retrieve relevant chunks.
- Choose a language model for the generation component.
- Implement a query engine that combines retrieval and generation.
- Optionally, enhance the query engine with techniques like retrieval augmentation, re-ranking, or multi-stage retrieval.
- Evaluate the RAG system's performance on metrics like answer relevancy, faithfulness, and retrieval quality.
- Iterate and refine the components based on evaluation results.
- Deploy the RAG system for production use.
Why RAG?
Fine-tuning (FT) and Retrieval-Augmented Generation (RAG) are two primary methods for customising large language models to domain-specific use cases.
Consider the following analogy, where we have two individuals who want to be doctors. The first individual has deeply studied and practised medicine over an extended period, gradually building up significant internalised knowledge. This is analogous to fine-tuning, where we train a model to specialise in domain-specific data given sufficient time and resources. The second individual is significantly less experienced than the first, but he has the uncanny ability to reference any information source accurately and fast, granting him quick access to a wide range of medical information. This is analogous to RAG, where we have a general-purpose LLM with access to a comprehensive knowledge base.
Put to the test, we find that the first individual is no doubt the better doctor. While the second individual has immediate access to information and the benefit of citing sources, he may not be as efficient or accurate as the first individual who has years of experience under his belt. However, what if the subject matter is changed from Medicine to Law? The first individual is too specialised and the new domain will be out of his depth. On the other hand, the second individual, with his ability to access any information source, can adapt quickly by referencing relevant legal information.
This analogy demonstrates why RAG is advantageous – it allows developers to build domain-specific generative AI solutions using general-purpose models, circumventing the higher barriers to entry required by model fine-tuning. RAG is more efficient and adaptable, making it the preferred choice for building accurate and scalable inference engines from different knowledge bases1.
Use Cases
Question Answering
RAG harnesses the power of large-scale text corpora to provide contextually rich responses. By retrieving relevant passages from a knowledge source and then generating answers using sophisticated language models, RAG ensures that the answers are not only accurate but also contextually appropriate. This integration allows RAG to handle a wide range of questions across different domains with a high degree of accuracy.
Summarisation
RAG introduces a new approach for summarizing extensive texts into concise and informative summaries. Rather than solely relying on extractive methods, which might overlook essential contextual details, RAG utilizes its retrieval component to pinpoint crucial passages from the document corpus. These passages then serve as a blueprint for the language model, guiding the creation of a coherent summary. This hybrid strategy allows RAG to generate summaries that are both comprehensive and faithful to the original context and nuances present in the source documents.
Drafting
In drafting or content generation tasks, RAG serves as a powerful tool for generating high-quality text from prompts or outlines. Whether it's writing essays, articles, or creative stories, RAG leverages its retrieval component to gather relevant information from a vast knowledge base. This information is then used to inform the generation process, ensuring that the generated text is both informative and contextually relevant. By combining retrieval-based context with generation-based fluency, RAG can produce content that closely aligns with the desired prompt or topic, making it an invaluable tool for content creators and writers.
-
Note that fine-tuning and RAG are not mutually exclusive solutions. As we discuss in later sections, RAG systems can also benefit from fine-tuning both embeddings and completion models, particularly in domains with specialised jargon. ↩