Options for Building an RAG Application
Plenty of options are available for building RAG applications, and the level of technical skills required range from no-code solutions, to solutions using open-source coding frameworks which you can fully customise to your needs. In this section, we discuss some of the options available for building an RAG application in GCC. Due to the large number of options available in the market, our objective is not to cover every option available. Instead, we categorise them by the level of technical skills required, and give examples of popular solutions in each category, so that the reader has some points of references if they are unsure how to get started.
One common issue faced by public service app builders is that of data classification and data residency (e.g. can I use Vertex AI Search for CONFIDENTIAL data?). As both the policy guidelines and landscape are fast-changing in this space, we will not attempt to map the solutions to the use cases’ data classifications as they will very quickly go out of date (e.g. Data which previously could not be sent to a service hosted overseas is now allowed with a waiver due to changes in guidelines; Cloud Service Provider decides to host the service in Singapore due to business demands). The reader is advised to verify that the chosen solution fulfils the requirements as stipulated in the policy guidelines at the time of implementation.
Getting Started: No-code/Low-code End-to-End Solutions
Technical expertise required: Low Customisation level: Low
This category of solutions is the easiest way to get an RAG app up and running. They typically involve simply uploading raw data to cloud storage and selecting some application parameters. The managed service will build the RAG application end-to-end, from data processing to deployment.
Cloud
AI Bots
AIBots is a platform built by GovTech which allows agencies to create AI Chatbots with pre-configured system prompts and an added knowledge base (.pdf, .docx, .txt files) using RAG. Public service officers can easily and quickly create a chatbot for their own agency's data by uploading their documents using a simple drag-and-drop user interface. Not only is it suited for beginners who do not have any programming background, advanced users can also use it to quickly build an RAG app to see what is the baseline performance, before deciding if more sophisticated custom development is required.
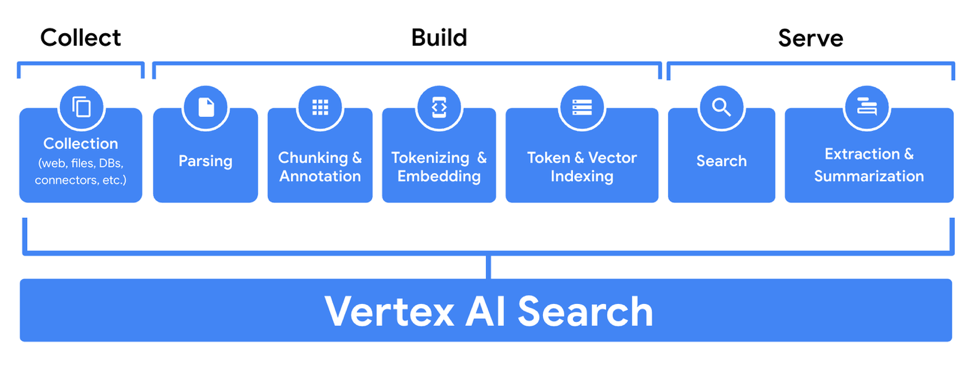
Vertex AI Search
Another convenient solution, available on GCC, is Vertex AI Search. Search is a big part of the RAG pipeline: You need to get the most relevant documents from your knowledge base to ensure that the completion model can have the most relevant context to answer the question or generate a summary. Google, being the market leader in information retrieval, has built in its latest technologies into the search pipeline. Despite its name, Vertex AI Search is more than just search. You can choose to add one of Google’s LLMs (e.g. Gemini, Bison) to do extraction, summarisation, or question answering.If a conversational UI is required, a Google DialogFlow module could be attached to it, to complete the app.
The search pipeline can be easily built using the console, as shown in this video, or by following the instructions on this website. Alternatively, you could also build the pipeline using code, as shown in this notebook.
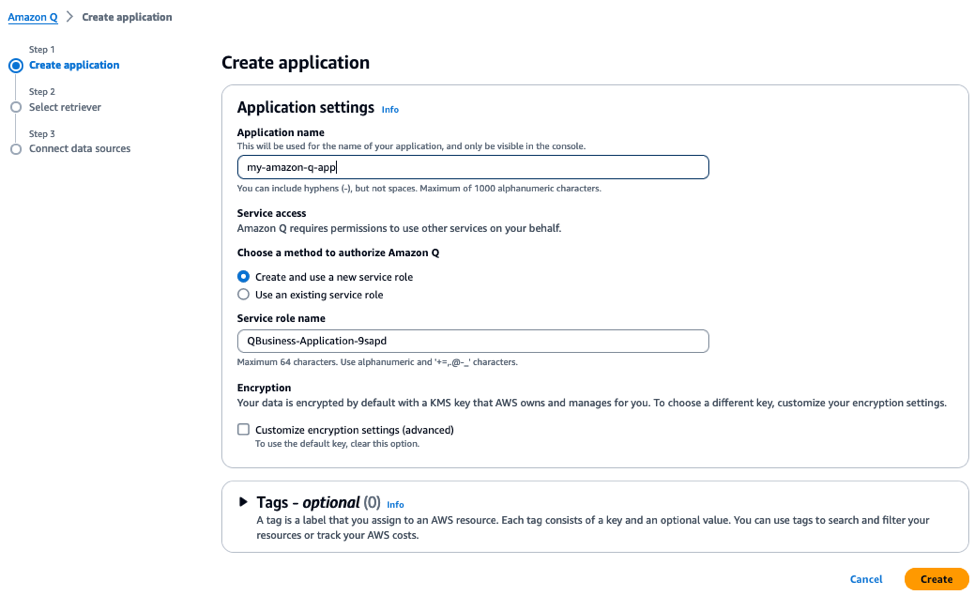
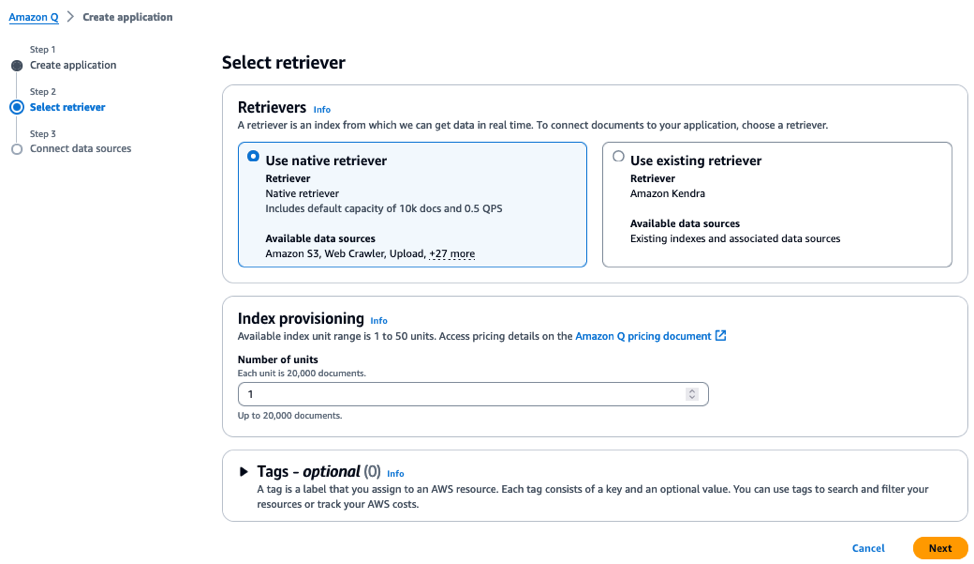
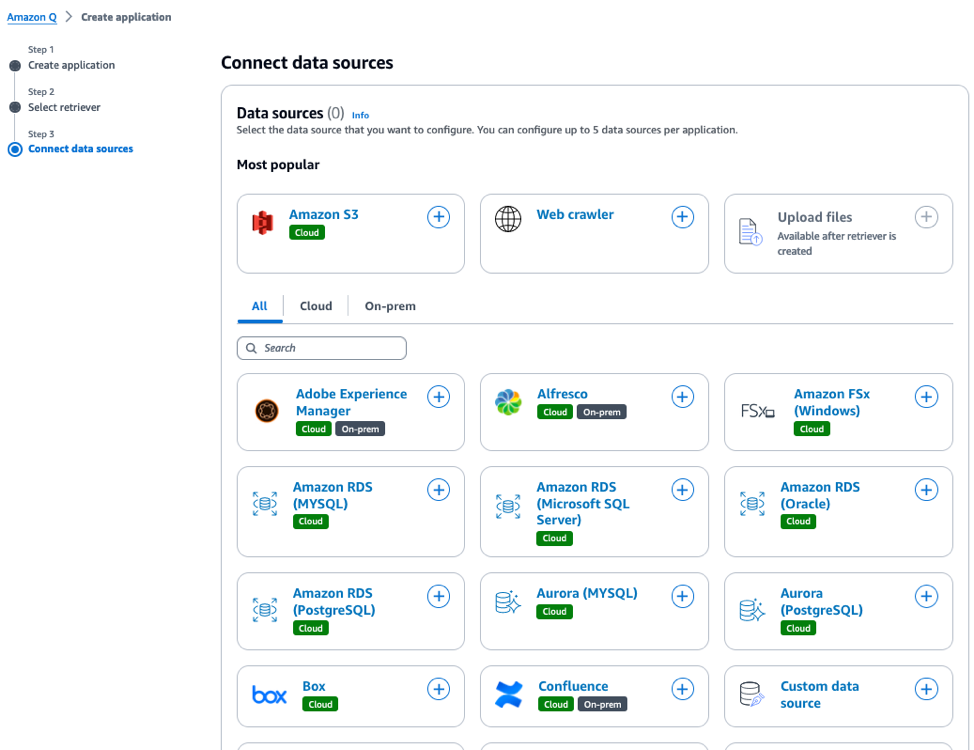
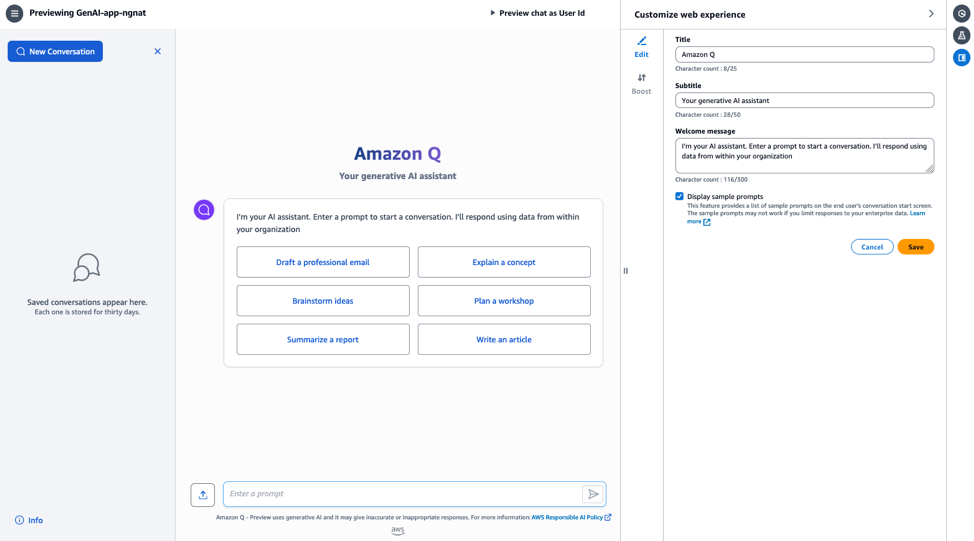
Amazon Q
Like Vertex AI Search, Amazon Q helps users to build Generative AI-powered conversational apps end-to-end. After your documents have been uploaded to a cloud storage like S3, a conversational app can be built in as few as four steps:
Local
AnythingLLM
AnythingLLM is a comprehensive AI application that simplifies the integration and use of advanced AI technologies, offering capabilities like Retrieval-Augmented Generation (RAG) and AI agents without requiring coding skills or dealing with infrastructure complexities. It is designed for users who want a zero-setup, private solution that combines multiple AI functions, including local language models and AI agents, into one platform. Additionally, it caters to businesses and organizations by providing a fully customizable, private AI application that functions like a full ChatGPT, supporting various language models, embedding models, and vector databases with advanced permissioning features. Explore AnythingLLM Desktop for a seamless start or leverage its enterprise options for tailored needs.
GPT4All
GPT4All is an open-source ecosystem designed to make it easy for anyone to deploy and use large language models (LLMs) on local hardware. It aims to democratize access to advanced AI technologies by providing tools and resources that allow users to run these models without requiring cloud services or extensive technical expertise. The ecosystem includes pre-trained models, software libraries, and documentation to facilitate the deployment of LLMs for various applications such as chatbots, content generation, and more, ensuring privacy and control over the data.
Intermediate: Platforms to Build Your Own Pipelines
Technical expertise required: Low Customisation level: Medium
While the previous category of solutions is convenient and takes very little effort to build and RAG app, they lack customisation and flexibility. The components for the whole end-to-end pipe are fixed and everything is processed automatically at the click of the button. However, there are times when modifications to the intermediate components are necessary. For example, you might need to chunk your documents in a different way, or use a custom embedding model for a specialised domain.
GCC Cloud Service Providers' Platforms
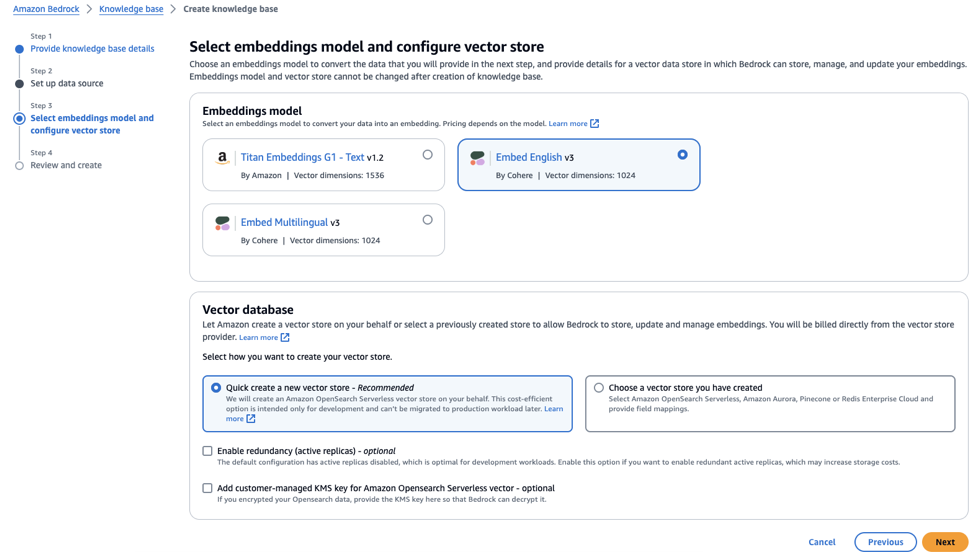
Platforms provided by CSPs on GCC like Amazon Bedrock provide such flexibility by allowing you to mix and match your own components within the platform, and even making API calls to other components outside the platforms. Amazon Bedrock is a fully managed service that offers a variety of large language models from different AI companies. Compared to Amazon Q, AWS Bedrock provides more flexibility in terms of the components which go into the pipeline - e.g you are able to select your own vector store, embedding model, and completion model. The steps below show how you can do this:

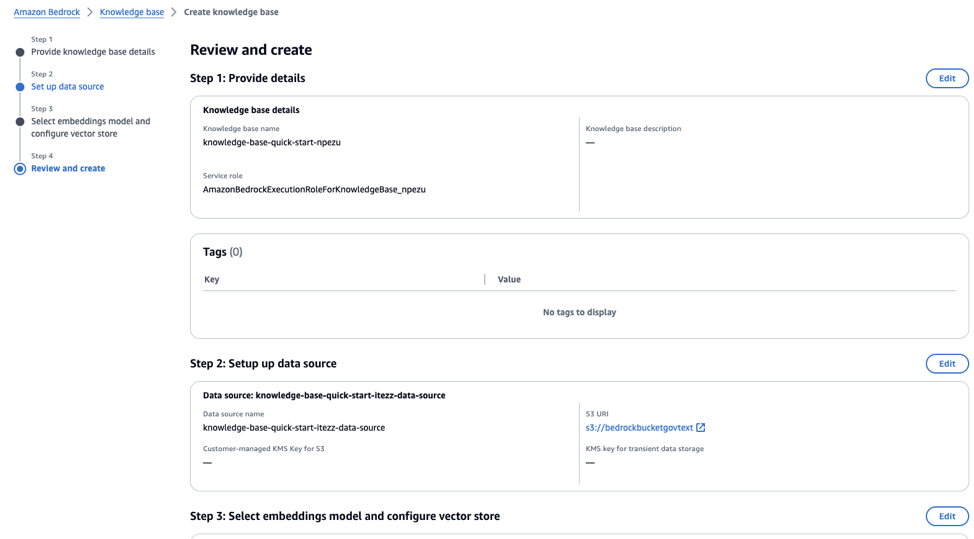
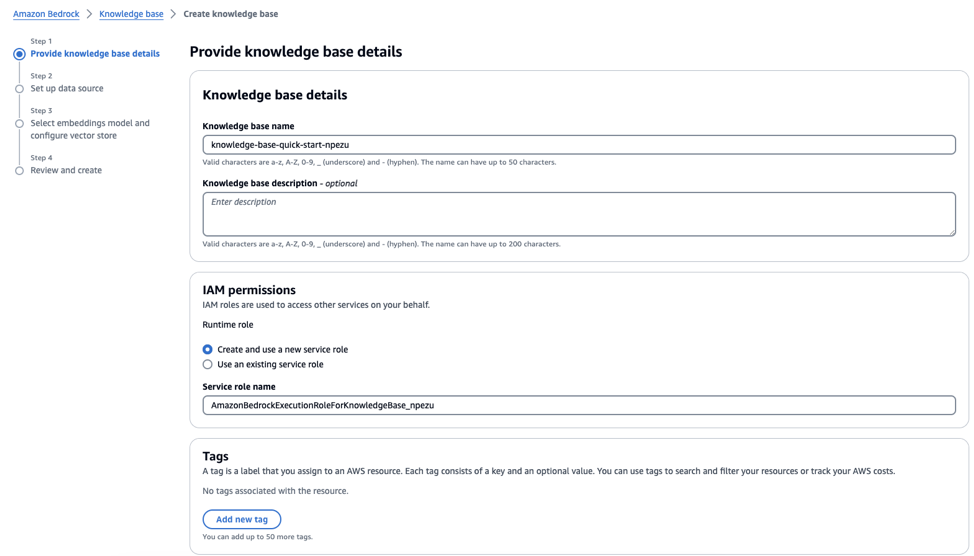
GovTech’s Central LLM Stack
The Central LLM Stack, developed by GovTechm is a comprehensive platform designed for the rapid prototyping and production launch of LLM-powered applications. It provides ready-made reusable templates that can accelerate the development of LLM-powered apps in just minutes, reducing the time and effort required for deployment. Additionally, the stack offers a suite of components specifically tailored to enhance LLM operations, including quick model evaluation and user feedback on response performance. What sets it apart is its accessibility, which can be achieved either through Direct APIs for advanced users or a user-friendly drag-and-drop interface for those seeking a more intuitive experience. Its overall architecture is as follows:
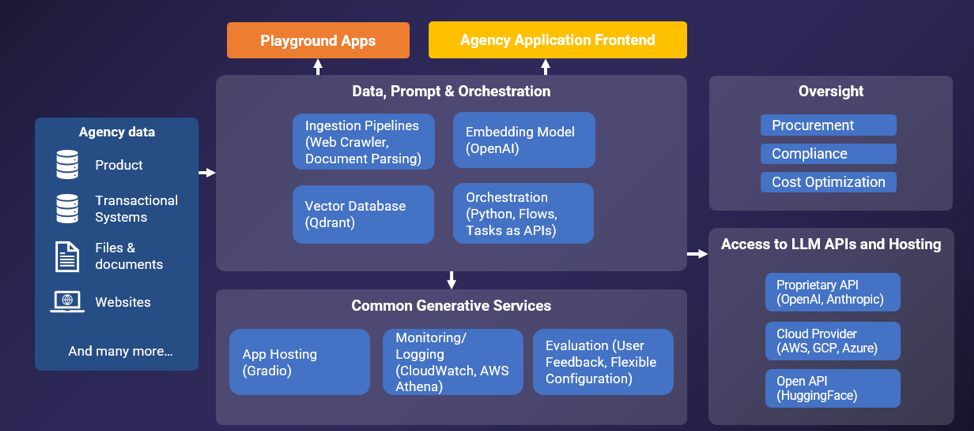
Like the CSPs’ platforms, it allows users to build RAG applications by mixing and matching different components. On top of that, it addresses a specific pain-point faced by RAG developers in the WOG by handling the procurement of LLM services and legal clearance so that the user can focus on app development without having to go through the processes of registering for CSP accounts and getting LLM credits. WOG app developers also would not have to worry about compliance issues as it is built in GCC, uses a scalable IM8-compliant infrastructure, and can store data up to Confidential (Cloud-Eligible).
Advanced: Open Source Frameworks
Technical expertise required: High Customisation level: High
There are situations when developers do not want to, or are not able to make use of the above-mentioned solutions.
Some of the reasons might include:
- They are not able to use cloud solutions because of the data classification
- They want complete control over the entire application pipeline for security reasons
- They want to use features which might not be available in the pre-built solutions
- They do not want their application to be locked-in to SaaS vendors, or even internal products
In such cases, developers may choose to use open source frameworks to build their RAG pipeline. Here are some popular solutions:
Langchain
LangChain is one of the most popular frameworks for developing Generative-AI applications, and is often used to build RAG pipelines. This framework consists of several parts.
- LangChain Libraries: The Python and JavaScript libraries. Contains interfaces and integrations for a myriad of components, a basic run time for combining these components into chains and agents, and off-the-shelf implementations of chains and agents.
- LangChain Templates: A collection of easily deployable reference architectures for a wide variety of tasks.
- LangServe: A library for deploying LangChain chains as a REST API.
- LangSmith: A developer platform that lets you debug, test, evaluate, and monitor chains built on any LLM framework and seamlessly integrates with LangChain.
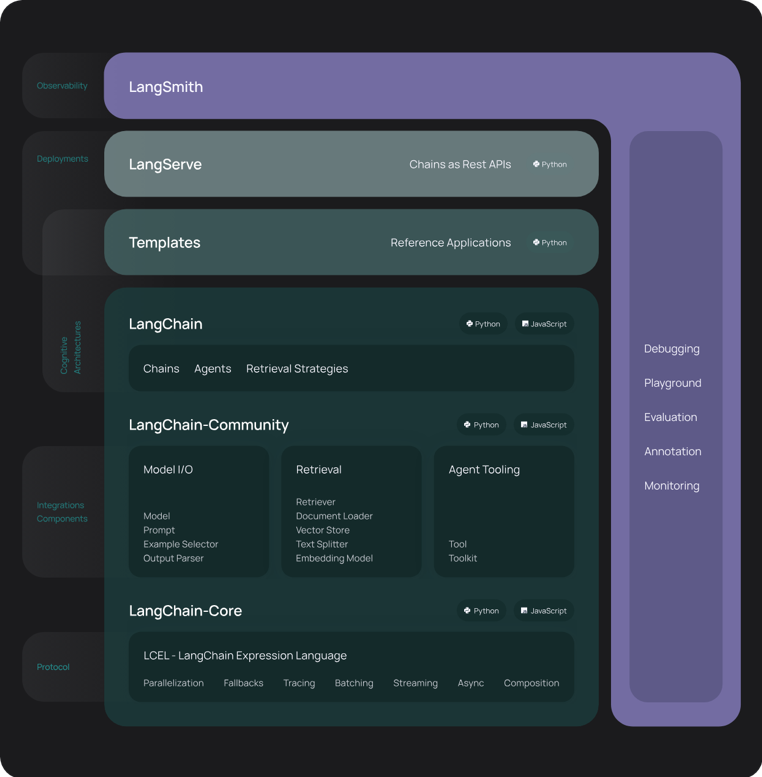
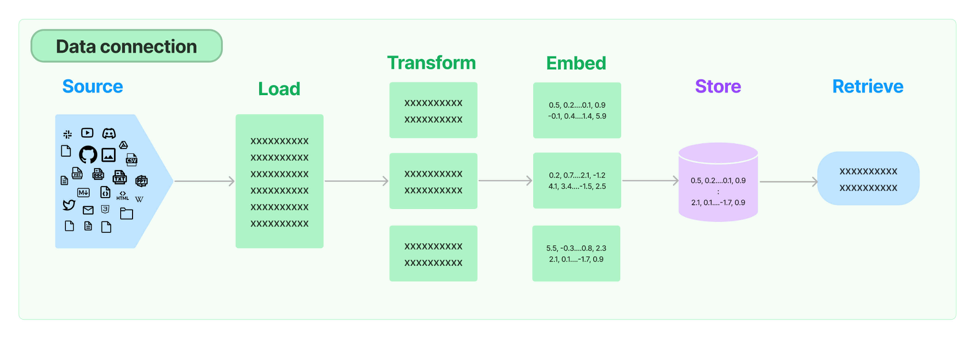
LangChain provides all the building blocks for RAG applications - from simple to complex. This page of the documentation covers everything related to the retrieval step. The beauty of it is that it’s not just a uniform standardised pipeline: For each retrieval step, there are various options available to modify your pipeline and this can be done with just a few lines of code changes.
For example, the conventional way of retrieving relevant documents is to use simple semantic search where the query is embedded and documents with the top k most similar embeddings are used as the relevant documents. If we want to use a more sophisticated retrieval method (these will be discussed in more detail in Part 2 - Optimising Document Retrieval) like Hybrid Search (if it is supported by the vector store) or Hypothetical Document Embeddings (HyDE), we can easily switch to them using Langchain.
Similarly, one can also easily switch between Document Transformation modules, Embedding models, and Vector Stores to experiment with different ones and see which perform better.
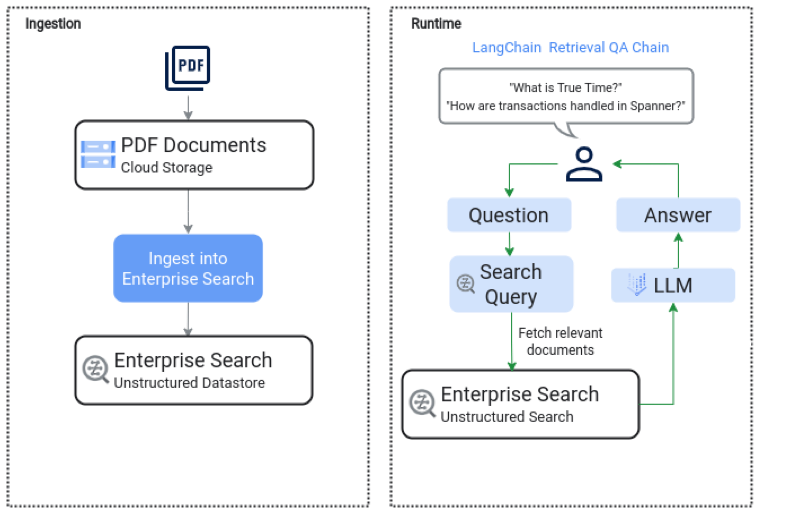
Langchain also supports integration with the no code/low code solutions mentioned above to build apps in Langchain if you do not want to run everything on the CSP’s platform or if there are Langchain modules you want to add to your pipeline for enhanced processing. This notebook shows how you can build a question answering app using Vertex AI Search and Langchain.
LlamaIndex
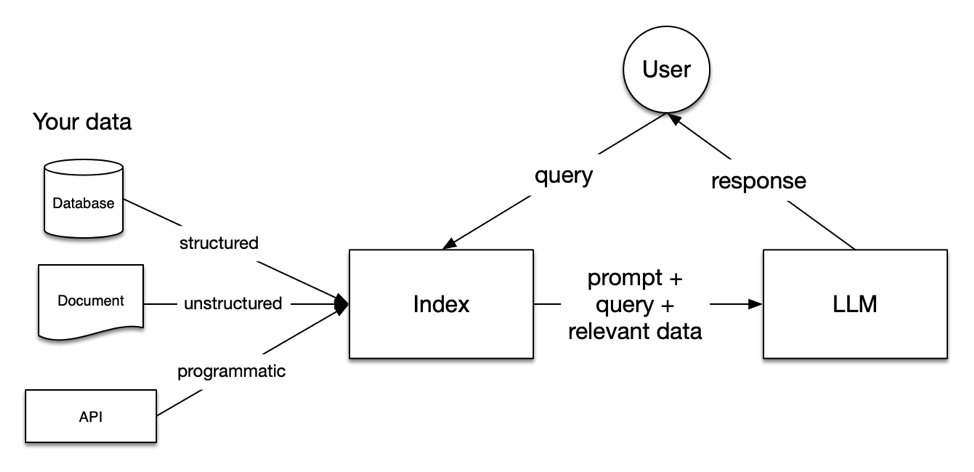
LlamaIndex is more specifically built for RAG applications because unlike Langchain which has a more rounded support for generative AI applications, LlamaIndex has a heavier focus on indexing, which is a critical part of the retrieval process. It provides the essential abstractions to more easily ingest, structure, and access private or domain-specific data in order to inject these safely and reliably into LLMs for more accurate text generation. For instance, LlamaIndex provides convenient abstractions for advanced methods like small-to-big retrieval and recursive retrieval, whereas implementing these in LangChain would require knowledge of how to build a custom retriever.
Like Langchain, LlamaIndex supports many kinds of different integrations and customisations. Their customisation tutorial shows you how to do so for different scenarios. For developers who want low level control of their pipeline so that they can optimise at that level, LlamaIndex also supports that. You can follow this low level retrieval guide to build your own low-level retrieval pipeline.